
안녕하세요.
오늘 가지고 온 논문은 최근에 관심이 생긴 Test-Time Adapation(TTA) 분야의 논문입니다.
기존에 제가 리뷰하던 UDA(Unsupervised Domain Adaptation)분야는 source와 target dataset이 명확하게 정해져 있어야 하고, 모델 학습 시에 target dataset이 존재해야 하는 반면, TTA는 UDA의 이러한 제한 사항으로부터 자유롭습니다.
그렇기 때문에 실제 application 적인 관점에서 Domain Generalization(DG) 분야의 논문과 함께 많이 연구되고 있습니다.
본 논문을 읽게 된 건 최근 TTA 분야에 대한 관심이 생겼던 것도 맞지만, 우연히 KAIST RCV 출신 우상현 교수님(CBAM 저자) 의 CV를 보다가 가장 최근 publish 된 논문이 오늘 리뷰할 이 논문이여서 한번 읽어보게 되었습니다.
또한 본 논문의 저자인 송준하씨 같은 경우에도, 블로그를 몇번 방문해서 양질의 리뷰와 글을 읽은 적이 있어서 더욱 읽어봐야겠다라는 생각이 들기도 했구요.
오늘 이후부터 아마 TTA(Test-Time Adaptation) , 그리고 DG(Domain Generalization) 분야를 계속해서 일단 읽고 리뷰하게 될 거 같네요.
그럼 바로 리뷰 시작하도록 하겠습니다.
1. Introduction
우리가 보통 모델을 학습시킨 후, 학습된 모델을 실제 상황에 test 하는데 까지는 크게 2가지 종류의 데이터 셋이 필요하게 됩니다. 학습을 진행하는 source domain dataset과, 실제 test를 진행하는 target domain dataset이죠.
하지만 당연한 소리로 source domain에서 학습된 모델을 그냥 target domain 에 바로 적용시켜 버리면 domain gap 으로 인해 큰 폭의 성능 하락이 발생하게 됩니다.
1.1. Unsupervised Domain Adaptation (UDA) & Domain Generalization (DG)
그래서 이러한 domain gap을 해결하고자 Unsupervised Domain Adaptation(UDA), Domain Generalization(DG) 등의 연구들이 활발하게 진행되고 있습니다.
이 중 제가 자주 리뷰하던 UDA 의 경우에는 모델을 학습시킬 때 gt가 존재하는 source domain dataset과, gt가 없어도 되는 target domain dataset이 모두 필요하게 됩니다.
하지만 앞서 수행되었던 UDA 연구는 실제 real driving scene에 적용하는 관점에 있어서 크게 2가지 문제점이 존재하게 됩니다.
- 우선 target domain으로의 adaptation을 위해서는 target domain을 직접 사용해서 모델을 학습시켜야 합니다.
하지만 실제 산업 환경에서 target domain dataset을 미리 구축하고 정제하는데는 어려움이 존재하죠. license 등의 문제도 수반될 수 있을 뿐더러, 설령 있다고 한들 target domain의 모든 영역을 커버하는 dataset을 구축하는건 사실 불가능에 가깝습니다. - 학습에 사용된 target domain 말고 또 다른 새로운 domain 환경에 배포를 하게 될 경우에도 문제가 발생합니다. 설령 A라고 하는 source domain dataset으로 모델을 열심히 학습 시킨 다음, B라고 하는 target domain에 대해 UDA로 adaptation을 잘 수행한 모델이 있다고 합시다.
해당 모델을 탑재한 이동체 로봇을 실제 환경에 배포했을 때 UDA 수행때 학습 한 B domain 말고 C, D 등 또 다른 domain을 만나게 될 경우가 문제라는 것이죠.
그리고 위에서 설명드린 application적인 관점에서 UDA 방식의 문제점은 사실 DG 에서도 유사하게 발생한다.
결국 Domain Generalization이라는 것이 A,B,C 등 각 domain에 대해 Domain specific한 정보를 모델링 하는것이 아니라, 모든 domain을 아우르는 공통된 Domain agnostic한 정보를 모델링하고 학습하고자 하는것이 DG의 핵심입니다.
이를 다시 말해보자면, A B C domain에 대해 열심히 generalization 된 모델을 학습시켜 놨는데 D라는 domain이 딱 하고 test time때 등장하면 말짱 꽝이라는 거죠.
1.2. Test-Time Adaptation (TTA)
사실 UDA 혹은 DG 기법을 이렇게 열심히 설계하는 것 보다 훨씬 더 좋은 방법이 있긴 합니다.
바로 모델이 실제 상황에서 만날법한 모든 case들을 잠재적인(potential) target domain datasets로 구성하고 이에 대해 모델을 미리 학습시켜버리는 것이죠.
하지만 이러한 방식은 당연히 말이 안됩니다. 매우 expensive 할 뿐더러, 모든 case들로 구성하기란 불가능하죠.
위에서 언급드린 UDA와 DG의 문제점을 해결하고, 바로 위 단락에서 말씀드린 부분을 변화구로 해결하기 위해 등장한 연구가 Test-Time Adaptation (TTA) 입니다.
TTA는 이름에서도 유추가 가능한 것 처럼 test 시에 adaptation이 수행되는 것입니다.
조금 더 구체적으로 말하자면, 모델을 우선 source domain에 대해 pretrain 시킨 뒤 실제 target scene에서 test를 진행하면서 inference를 함과 동시에 adaptation이 동시에 진행되는 방식입니다.
그렇기 때문에 미리 target dataset을 구성해야 한다는 기존 UDA, DG 에 비해 훨씬 더 application 적인 장점이 있죠.
TTA의 컨셉 상 실제 환경에서 test를 함과 동시에 adatpation 까지 같이 수행되기 때문에
로봇이 새로운 domain에 대해 빠르게 adaptation 하고, 시간이 지남에 따라 점점 더 견고하게 성능을 낼 수 있다는 점에서 robotics system에 탑재하기에 아주 적합한 기법입니다.
이런 TTA 연구도 예전부터 꽤나 활발하게 진행되고 있습니다.
하지만 제가 TTA 분야에 대해 공부하고 논문을 읽은 지 오래는 되지 않아서 이전 연구들에 대해 자세하게는 설명드리기 어렵고, 제가 아는 선으로 간략하게 이전 연구들의 핵심 포인트에 대해서만 소개 드리도록 하겠습니다.
1.2.1. previous TTA - TENT
'[ICLR 2021 spotlight] Tent: Fully Test-time Adaptation by Entropy Minimization' 논문에서 제안한 TENT 라고 하는 기법입니다.
본 논문에서는 TTA를 수행할 때 모델에서 Batch norm layer를 제외한 모든 layer의 parameter를 freeze 시켜 버립니다.
그 후 모델 예측의 entropy(불확실성)을 줄이는 방향으로 loss function을 설계해서 TTA를 수행하게 됩니다.
사실 BN layer를 제외한 모든 layer를 freeze시키고 BN layer의 parameter만을 가지고 update를 수행한다는 것이 adaptation적인 관점에서 어떤 작용을 하는지에 대해서는 TENT 논문을 읽어보지 않아서 정확히 잘 모르겠습니다.
(곧 읽을 예정입니다 ㅎ)
다만 TENT 방식에서 사용한 BN layer를 제외한 모든 layer를 freeze 시키는 방식을 많은 TTA 방법론, 그리고 오늘 리뷰할 논문에서도 해당 방식을 사용하기 때문에 꽤나 중요한 역할을 하나봅니다.
(+참고로 TENT 논문이 TTA 분야에서는 baseline 논문 격이라고 하네요)
1.2.2. previous TTA -EATA
다음으론 '[ICML 2022] Efficient test-time model adaptation without forgetting' 논문에서 제안한 EATA 기법입니다.
해당 논문의 핵심은 아래 2가지로 정리할 수 있습니다.
1. 모든 test sample이 adaptation에 동일하게 기여하는 것은 아니다.
오히려 entropy가 높은 sample 은 noise로 적용할 수도 있음.
이를 위해 active sample selection criterion 을 제안함.
2. 학습 중, 후반부에 갈수록 발생하는 forgetting issue를 완화하기 위한 regularization term 설계
결국 위 1번을 보니 EATA 기법은 TTA를 수행하는 데 있어서 active learning 적인 아이디어를 접목시켰네요.
그리고 2번에서 설계한 regularization term은 본 논문에서도 동일하게 사용하고 있는 기법입니다.
자 이렇게 크게 2가지 TTA 방법론들에 대해 살펴봤습니다.
위 방법론들이 꽤나 완벽한 성능을 보일 것 같음에도 불구하고 본 논문의 저자는 앞선 방식들에 공통적인 문제점이 있다고 주장하게 됩니다. 아래 그림과 함께 설명 드리도록 하겠습니다.
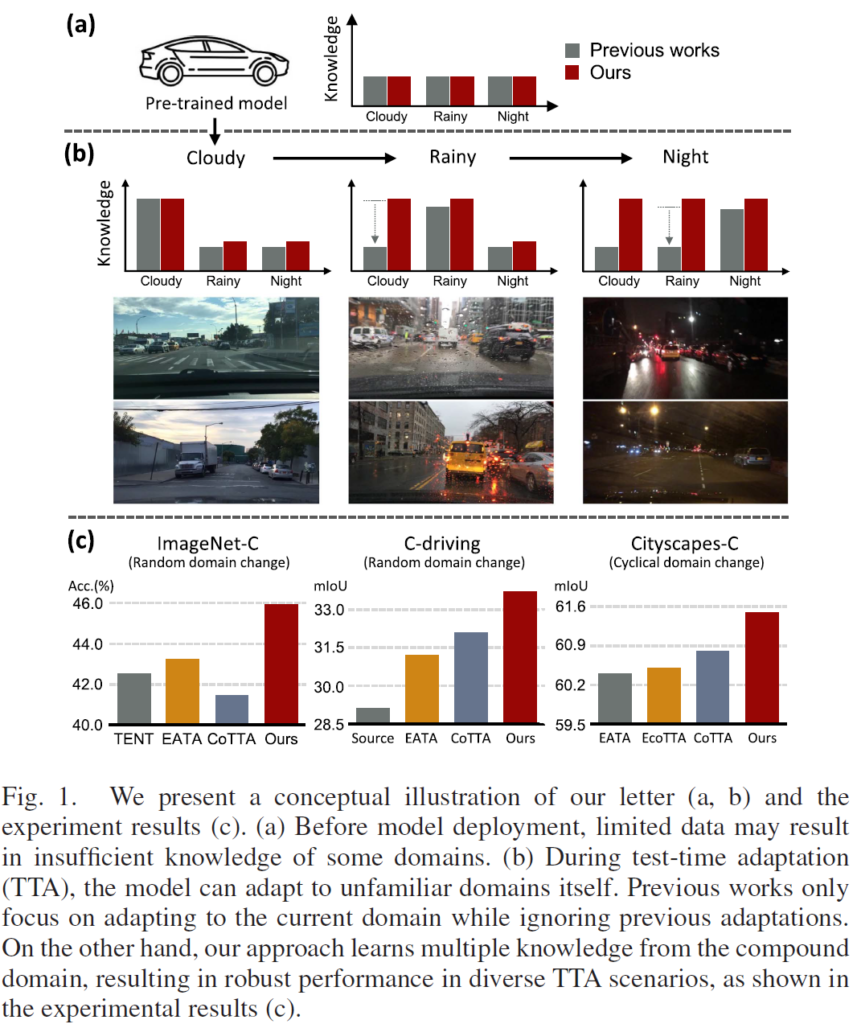
<그림 1 - (a)>
우선 TTA의 특성 상 Test-Time에서의 Adaptation을 수행하기 전에 선행되는 것이 바로 모델을 source domain에 대해 학습 시키는 것입니다.
위 그림 1의 (a)가 이를 나타낸 그림인데요, source domain에 대해 모델을 학습시킨 뒤 우측의 그래프를 보시면 cloudy, rainy, night 와 같은 서로 다른 domain에 대한 지식(knowledge)를 어느정도 학습한 것을 볼 수 있습니다.
previous works와 ours 모두 동일한 양의 지식을 학습했네요.
(아직 TTA 수행 전이니 너무나도 당연합니다)
<그림 1 - (b)>
이후 위 그림 1 (b) 에서 보시는 것 처럼 previous works와 ours 모두 TTA 가 수행 되는 것을 볼 수 있습니다.
화살표를 보면 아시다시피 cloudy->rainy->night domain 순으로 TTA 가 진행되고 있습니다.
다만 TTA가 수행되면서 학습하는 지식(knowledge) 그래프에 집중해서 보면 기존 works 들과 본 논문 방식의 차이점을 명확하게 알 수 있습니다.
기존 연구들은 여러 하위 target domain에 대한 각각의 지식(knowledge)을 모두 잘 고려하지 못하고, 현재 adaptation을 수행하고 있는 current domain에 대해서만 집중하는 것을 볼 수 있습니다.
그렇기 때문에 이전에 adaptation을 수행해서 얻었던 지식(knowledge)은 버려지는 것을 볼 수 있죠.
rainy에 대한 adaptation이 수행되면서 cloudy의 지식(knowledge)이 버려지고, 이와 마찬가지로 night에 대한 adaptation이 수행되면서 rainy의 지식(knowledge)이 버려지는 것을 볼 수 있습니다.
본 논문에서는 이를 해결하고자 TTA 모델이 여러 복합적인 test domain으로 부터 지식(knowledge)을 잘 관리하고 보존하도록 합니다. 본 논문에서는 이를 compound domain knowledge management 라고 표현하고 있네요.
자세한 방법론에 대해선 method에 대해서 설명드리겠습니다.
<그림 1 - (c)>
3가지 dataset에 대한 실험 결과를 보시면 본 논문의 performance 를 명확하게 알 수 있습니다.
결국 본 논문에서는 타 방법론과는 다르게 이전에 adaptation을 수행하면서 얻었던 지식(knowledge)에 대해서도 잘 보존하고 있을테고, 이 말은 즉슨 TTA 수행 시 그 어떤 상황이 random하게 들이닥쳐도 이전에 얻었던 지식(knowledge)과 유사하다면 잘 예측해 낼 수 있는 것입니다.
이를 입증하고자 그림 1. (c) 에서는 3가지 dataset에 대해 random domain change를 적용하면서 각 TTA 방법론들과의 정확도(Acc) 비교를 수행했습니다. 확실히 타 기법들에 비해 좋은 결과를 보여주고 있는 것을 볼 수 있습니다.
이를 좀 더 자율주행 관점에서 풀어보자면,
터널, 햇빛 비침, 안개, 비 등 dynamic하게 domain이 변화하는 과정에서도 이전에 얻은 지식(knowledge)이 있다면 이를 까먹지 않고 잘 보존했기 때문에 타 방법론들에 비해 정확한 예측을 수행할 수 있는 것입니다.
네.. introduction이 좀 길었던 거 같습니다.
아무래도 TTA 분야에 대해 처음 리뷰를 작성하다 보니 서론에서 이것저것 설명드릴 부분이 많아서 많은 분량을 차지한 거 같네요.
그럼 본 논문의 contribution을 빠르게 살펴보고 바로 method로 넘어가도록 하겠습니다.
- Dynamic domain shifts에도 효과적으로 잘 대응할 수 있도록 하기 위해,
compound(복합적인) domain knowledge를 관리하는 TTA framework 를 설계하였다. - compound(복합적인) domain 에서의 overfitting을 방지하기 위한 새로운 regularization term을 설계하였다.
- 이 부분에 대해선 위에서 설명을 조금 빠뜨린 거 같네요. 위에서 previous TTA 기법으로 소개드린 방법론 중 EATA에서 제안한 regularization term을 조금 변형해서 새롭게 설계한 것입니다.
method에서 자세하게 설명 드릴거기 때문에 간단히만 말씀드리자면 fog, night 등 여러 domain에 대해 TTA를 수행하게 될텐데 이 중 상대적으로 loss가 큰 domain에 대해서 수렴이 더 빨리 일어나기 때문에 해당 domain에서의 collapse가 빠르게 일어나버려서 이를 방지하고자 하는 것입니다.
마치 segmentation task 에서 class-balanced 방식으로 loss를 부여하는 것과 뭔가 느낌이 비슷하네요. - Classification과 Segmentation task에서 본 논문의 효과를 입증하였다.
2. Method
2.1. Prerequisite
TTA 모델은 여러 target domain에 대한 예측 정확도를 올리기 위해 test time 동안 inference 와 adaptation을 동시에 수행합니다. 이것은 모든 TTA 방법론들의 핵심 목표죠.
하지만, 기존 TTA 연구들은 target domain overfitting으로 인한 성능 저하의 문제를 피할 수 없다고 합니다.
overfitting이 발생하는 이유로는 크게 2가지가 존재합니다.
우선 여러 target domain 에 대한 지식들을 습득해야 하기 때문에 기본적으로 adaptation 과정을 오랫동안 수행하게 되는데, 이때 overfitting 문제가 발생할 수 있습니다. 오랫동안 수행하기 때문이죠.
또한 TTA는 test gt가 없는 상황에서 adaptation이 진행되기 때문에 unsupervised loss로 backpropagation을 수행하게 되는데 이때의 gradient 가 supervised loss에 비해 unreliable 하다는 문제도 발생합니다.
사실 이 문제는 overfitting을 발생시킨다기 보다는, 모델이 unreliable한 예측에 대해 bias되고 collapse 된다는 표현이 맞겠네요.
위에서 설명드렸다시피 앞선 TTA 방식들에게는 overfitting과 성능 저하의 문제가 발생합니다.
위와 같은 overfitting을 막기 위해선 adaptation을 일찍 중단하면 되는데, 이건 TTA 의 목적성과 부합하지 않습니다.
왜냐면 TTA에서 unfamilier target domain image가 언제 등장할 지 모르는데 adaptation 과정을 일찍 멈춰버리면 특정 domain에 대한 지식을 습득하지 못할 수 있기 때문입니다.
그렇기 때문에 본 논문에서는 adaptation 과정을 오랫동안 수행하는 것을 기본 세팅으로 합니다.
long-term TTA 라고 표현하고 있네요. 그리고 이런 long-term TTA가 진행 되면서 발생할 수 있는 overfitting 문제를 해결하기 위해 앞선 연구 중 'EATA' 에서 제안한 adaptation loss 와 weight regularization을 베이스라인 삼아 그대로 사용합니다.
(추가적으로 EATA 에서는 TTA 과정이 진행되는 동안 모델 내 BN layer를 제외한 모든 paramerter를 freeze 시키고 BN layer의 parameter만 update 시킵니다. 해당 방식을 본 논문에서도 그대로 차용합니다.)
adaptation loss
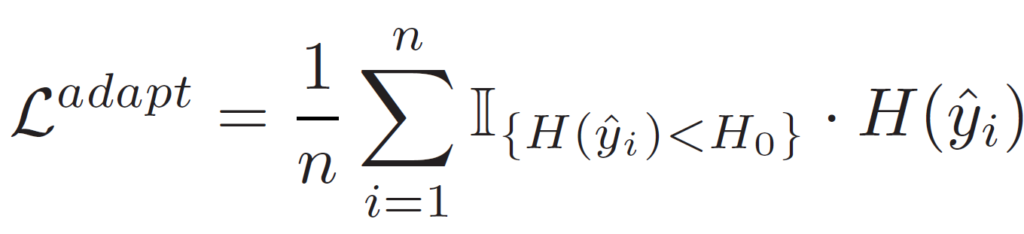
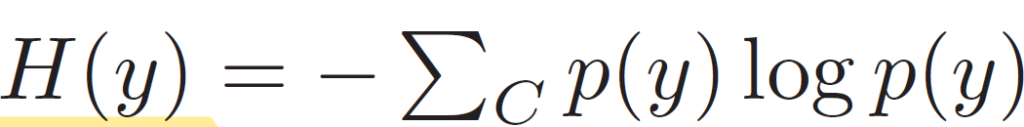
- $\hat{y}_i $ : logits output of $ x_i $
- $ \mathbb{1} $ : Indicator function (0 or 1)
- $ C $ : num of classes
- $ H_0 $ : pre-defined threshold
본 논문에서는 0.4 x ln C 를 사용 - $ p(.) $ : softmax function
Test-Time Adaptation을 위한 loss 입니다.
p(y)는 예측값의 softmax이고, H(y)는 softmax 값의 entropy(불확실성) 입니다.
그리고 이를 $ L_{adapt} $ 식에 적용시켜서 결국 entropy를 최소화 하는 방향으로 loss가 동작하는것입니다.
이때 indicator function을 통해 미리 설정한 threshold $ H_0 $ 보다 낮은 sample에 대해서만 loss 를 적용시키는 것을 볼 수 있습니다.
사실 이 부분은 이전 논문을 인용한 것이라 자세한 설명이 없는데, 아마 제가 추측하자면...
entropy가 $ H_0 $ 이상인 domain image에 대해서 loss를 backward 해 버리면 해당 domain에 대한 loss가 빠르게 수렴할 것이므로 타 모델에 비해 빠르게 collapse 되는 문제가 발생합니다.
그래서 아마 이를 해결하고자 thresholding 을 한 것 같습니다.
weight regularization

- $ \tilde{\Theta} $ : adapted parameters of networks (ex. BN layers parameters)
- $ \tilde{\Theta}^o $ : frozen parameters of pre-trained networks
- $ w(\theta_i) $ : $ \theta_i $ 들 중 중요도에 따라 다르게 부여되는 가중치
(diagonal fisher information matrix 라는 것을 통해 계산된다고 함,,,)
또한 이전 방법론에서 제안된 overfitting을 방지하기 위한 regularization term도 사용합니다. 모델의 parameter가 너무 빠르게 수렴하는 것을 방지하기 위함이죠.
2.2. TTA Framework for Compound Domain Knowledge
실제 TTA가 적용되는 상황은 매우 동적(dynamic)하게, 다양한 environmental changes 를 마주할 수 있습니다.
가령 갑자기 터널로 들어간다거나, 빛이 세게 비추는 그런 상황이 되겠죠. 그렇기 때문에 이런 여러 domain 에 대해 복합적으로 잘 동작해야 합니다.
이를 위해 저자는 TTA 모델이 복합적인(compound) domain knowledge를 잘 수용(accomodate)할 수 있도록 합니다.
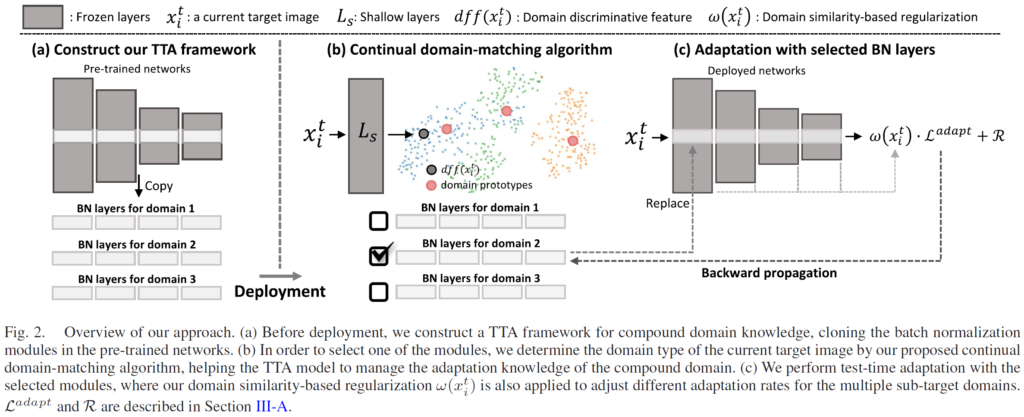
그렇게 설계한 모델 구조가 위 그림에 해당하는데, 각 요소 별로 아래 섹션에서 자세히 살펴보겠습니다.
2.2.1. Compound domain TTA framework
그래서 TTA에서는 어떻게 다양한 복합적인 domain을 다루는데? 라고 질문하실 수도 있습니다.
이전 연구들에서는 각 domain들의 다양한 지식(knowledge)를 효과적으로 학습하기 위해 domain-specific modules를 구성하였습니다.
위 그림 2의 (a)를 보시면 아래쪽에 BN layers for domain n (n=1,2,3) 이런 식으로 각 domain 별 BN layers가 구성되어 있는 것을 볼 수 있습니다. 구체적인 학습, 동작 과정은 아래와 같습니다.
본 절(2.2.1) 에서 설명드리는 내용은 이전 연구들의 흐름을 그대로 차용한 것으로 동작 과정은 이전 연구들과 동일합니다.
우선 TTA 모델을 실제 상황에 배포하기 전에 source domain dataset으로 부터 학습을 시킵니다.
그렇게 pre-trained된 모델을 freeze 시킨 뒤 BN layers들을 K개 만큼 복사해서 구성합니다. 위 그림 2의 예시에서는 3개로 구성되어 있네요.
사실 뒤에서 실험적으로 설명드릴 내용이긴 합니다만 TTA 모델이 실제 test 상황에서 몇 가지의 domain을 만날지 모르기 때문에 K는 실험을 통해 세팅하였습니다.
(이게 어떻게보면 K를 임의로 세팅해야 하기 때문에 TTA의 한계가 될 수도 있겠네요)
그리고 이렇게 복사된 K개의 BN layers를 가진 채로 TTA 모델은 실제 상황에 배포가 됩니다. BN layers parameters 말고 모든 parameter는 freeze된 상태입니다.
그리고 test 상황에서 이미지가 들어왔을 때, 들어온 이미지가 어떤 domain에 해당하는 지 domain type을 예측하고 해당 domain type에 맞는 BN layers를 적용시키는 방식입니다.
(K의 수가 참 중요해 보이죠??)
domain type을 어떻게 예측하는지는 바로 뒤에서 설명 드리겠습니다.
2.2.2. Domain distinctive features
test 상황에서 들어온 이미지가 어떤 domain type인지를 알아내기 위해 우선 domain distinctive features ddf 를 정의할 필요가 있습니다.
서로 같은 domain끼리는 유사한 ddf 를, 다른 domain 끼리는 상이한 ddf 가 추출되어야겠죠.
이를 위해 domain generalization 분야의 컨셉을 가져옵니다.
'[AAAI 2020] Domain generalization using a mixture of multiple latent domains' 논문에서는 style transfer 분야의 style features를 사용해서 domain specific하고 distinctive한 ddf 를 모델링합니다.
이를 요약하자면 모든 이미지는 색감등을 나타내는 style 과 엣지, 구조적 형태를 나타내는 content 로 구성되어 있는데, 이 중 domain이 달라진다 한들 content 속성은 유지되지만 style 요소는 변화합니다.
그 말은 즉슨 이미지 내에서 style 요소를 뽑아내면, 이것이 자기자신 domain을 표현하는 distinctive한 feature가 될 수 있다는 것이죠.
ddf 를 추출하기 위한 모델은 매우매우 간단합니다.
ResNet 의 conv1과 layer1 만을 사용하였습니다.
위 그림 2. (b) 에서는 해당 ResNet을 $ L_S $ 로 표기한것을 볼 수 있네요.
이를 모델링하는 식은 아래와 같습니다.
(위 논문의 식을 그대로 사용하였습니다)

- $ \theta_0 $ : ResNet conv1의 최종 출력
- $ \theta_1 $ : ResNet layer1의 최종 출력
- $ \mu $ : 평균
- $ \sigma $ : 표준편차
어쨌든 저자는 기존 Domain Generalization 분야를 사용해서 domain끼리 분별력이 있는 feature를 모델링하고자 이미지의 style을 추출해서 이를 domain feature vector ddf 로 사용하였습니다.
그림 2. (b) 를 보시면 입력 이미지 $ x_i $ 가 shallow ResNet인 $ L_S $ 를 통과해서 ddf 가 출력되는 것을 볼 수 있습니다.
2.2.3. Continual domain-matching algorithm
자 이렇게 각 domain을 대표하면서, 타 domain과는 분별력이 있는 ddf vector를 추출했습니다.
그럼 이제 이 ddf vector가 어떤 domain으로 부터 비롯되었는지를 예측해야겠죠?
저자는 이를 'pseudo-domain label' 을 결정해야 한다고 표현하고 있네요. 적절한 표현인거 같습니다.
그럼 이전 연구들은 어떻게 pseudo-domain label을 결정했을까요?
위 2.2.2. 에서 언급드린 [AAAI 2020] DG 논문에서는 kmeans clustering 기법을 사용했다고 합니다.
하지만 TTA 가 진행되면 진행될수록 이 kmeans clustering 기법은 시간이 많이 소요되겠죠?
저자는 이런 long running time 이슈를 해결하고자 continual domain-matching algorithm 을 설계합니다.
이름에서 알 수 있다시피 뭔가 continual~~ 하게 계속해서 ddf의 domain을 matching 해주는 기법입니다.
해당 알고리즘을 잘 나타내주는 그림은 아래를 보시면 됩니다.
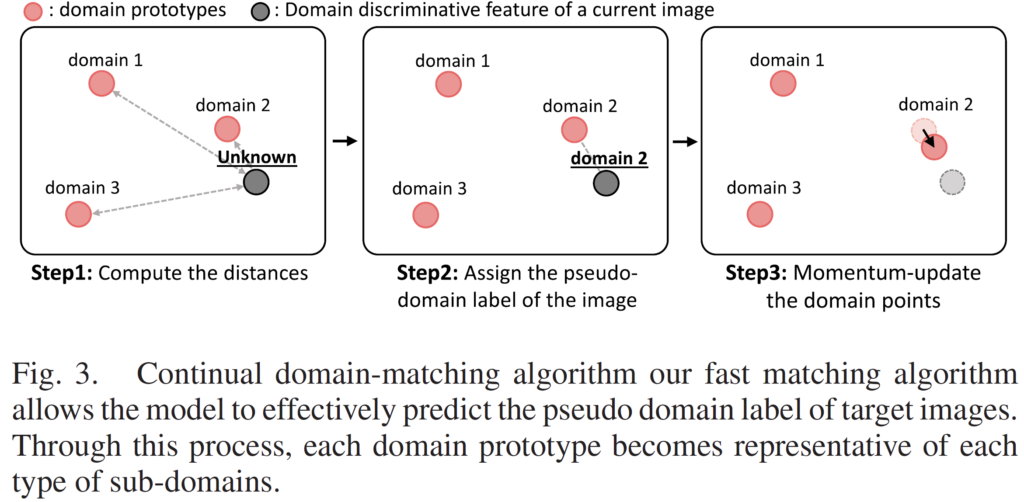
제 리뷰에서는 자주 등장하는.. prototype 친구가 또 등장했네요.
- 현재 이미지가 shallow ResNet인 $ L_S $ 를 통과하면 domain vector인 ddf 이 출력됩니다. 이는 현재 unknown 상태겠죠. 위 그림 step1에서 회색으로 표기되어 있습니다.
그 후 각 domain prototype과의 distance를 계산합니다. 위 그림에서는 K=3으로 세팅되어 있기 때문에 3개의 domain prototype이 존재하네요. domain prototype은 각 domain의 특징을 잘 담고있는 대표 vector 라고 생각하시면 됩니다. - 3개의 domain prototype중 가장 가까운 녀석의 index를 할당합니다. 위 그림 step2를 보시면 원래 unknown 였던 입력 ddf vector가 domain 2로 라벨링되어 있는것을 볼 수 있습니다. 저자의 표현으로는 'pseudo-domain label' 을 지정한 것입니다.
- step 3입니다. 선택된 domain prototype을 moving average 방식으로 update 해 줍니다. step 3을 보시면 domain 2 prototype이 회색 ddf 쪽으로 조금 가까이 이동한 것을 볼 수 있죠.
이런식으로 점차적으로 각 domain을 대표하는 prototype을 update해 나가면서 각 domain을 잘 대표할 수 있는 domain distinctive한 prototype을 모델링 해 나가는 것입니다. moving average update 식은 4번 아래를 보시면 됩니다. - 그리고 이렇게 입력으로 들어온 ddf vector에 대해 pseudo-domain label도 부여해주고, 기존 domain prototype을 update하는 과정도 거쳤습니다.
다음은 TTA를 수행하는 과정입니다. 이는 2.2절의 모델 전체 구조를 나타내는 그림 2. (b)와 (c)를 참고하셔야 합니다.
현재 ddf에 부여된 pseudo-domain label 이 domain 2 이기 때문에 (b)에서 3개의 BN layers 중에서 2번째 BN layer를 선택한 것을 볼 수 있습니다. 그리고 이는 (c)의 TTA 모델로 전달되고 forward와 backward를 통해 update가 진행되죠. 물론 이때 앞서 계속 반복해서 말씀드렸던 것 처럼 나머지 layer는 모두 freeze된 채 BN layers parameters만 update가 진행됩니다.
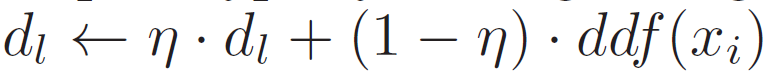
그리고 step 1에서 사용한 distance 계산 방식은 Bhattacharya function을 사용했다고 합니다.
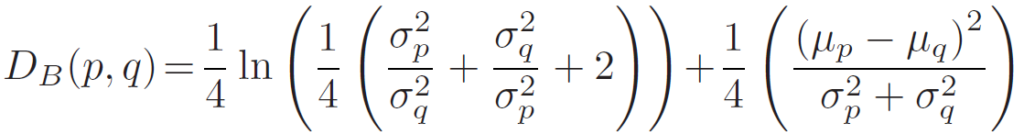
음 얼추 위의 1~4 알고리즘을 통해 TTA 가 어떤식으로 진행되는지는 이해하셨을거라 생각이 듭니다.
모델이 TTA를 수행하면서 각 domain을 나타내는 domain prototype이 점차적으로 update되면서 domain별 BN layer 또한 학습이 진행되는 뭐 그런 흐름입니다.
음,, 그렇다면 과연 TTA수행 전 초기 domain prototype은 어떻게 초기화가 된 채로 진행되는 걸까요?
사실 저도 너무 궁금한데 잘 모르겠습니다. 저자의 언급이 없을 뿐 아니라 코드도 아직 공개가 되지 않았거든요 ㅎ.
아마 domain prototype의 갯수를 나타내는 K를 미리 지정해줘야 하기 때문에 랜덤하게 K개의 domain prototype을 세팅하는 것이 아닐까요..? 라는 추측을 해 보며 다음 절로 넘어가겠습니다.
2.3. Domain Similarity-Based Loss Regularization
본 논문, 그리고 TTA 연구들이 타겟으로 하는 TTA 탑재 대상은 자율주행 차, 로봇 등의 엣지 디바이스에서 진행됩니다.
그리고 TTA가 수행되면서 입력으로 들어오는 이미지들에 대해 바로 adaptation을 수행하기 때문에 당연히 gt label이 없는 상황에서 unsupervised loss를 통해 TTA 모델 update가 진행됩니다.
가령 2.1.adaptation loss 절에서 설명드린 entropy minimization loss가 이에 해당하겠죠.
결국 TTA 모델은 unsupervised loss를 통한, noise가 포함된 gradient를 통해 backward가 진행되게 되고 이는 잘못된 방향으로의 모델 수렴이 일어나게 됩니다. 저자는 앞선 TTA 연구들에서 이러한 현상들이 발견되었다고 합니다.
그리고 이를 해결하고자 loss regularization term $ w $ 를 설계하게 됩니다.
저자는 앞선 TTA 모델들을 분석하면서 각 target domain 별로 error accumulation(누적) 속도가 달라지는 현상을 발견했다고 합니다. 예를 들면, night 이미지는 일반적으로 day 이미지보다 예측 정확도가 떨어질테고, 이는 즉 entropy가 크다는 것이니 loss가 더 큰 값을 가지게 됩니다.
결국 adaptation이 진행되면서 night은 day에 비해 더 빠르게 loss가 감소하게 됩니다. 즉 night-specific module 이 더 빠르게 collapsed 하는 overfitting 현상이 발생하게 되는것이죠.
이를 해결하고자 저자는,
만약 미리 pre-trained된 source domain과 크게 구별되는 target domain이 입력으로 들어왔을 때 error accumulation(누적)을 완화하는 term을 설계합니다.
구체적으로, 현재 입력으로 들어온 target domain 이미지에 대한 평균, 표준편차와 pre-train시 사용된 source domain의 평균, 표준편차를 통해 유사성을 계산하게 됩니다. 아래 식을 통해서 말이죠.
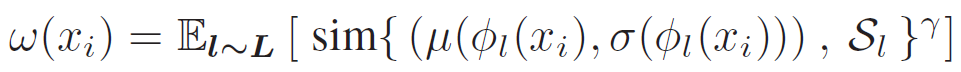
결국 앞선 TTA 모델들의 문제점이 source domain과 크게 구별되는 target domain의 모델(BN layers) 이 빠르게 collpased 된다는 것이였는데, 위 w를 통해 낮은 가중치를 부여함으로써 loss 수렴 속도를 낮출 수 있게 됩니다. similarity 값이 낮게 나올테니까요.
최종적으로 위 regularization term을 적용한 최종 loss는 아래와 같습니다.
total loss를 구성하는 각 loss들은 2.1. 절에서 설명드린 것과 동일합니다.
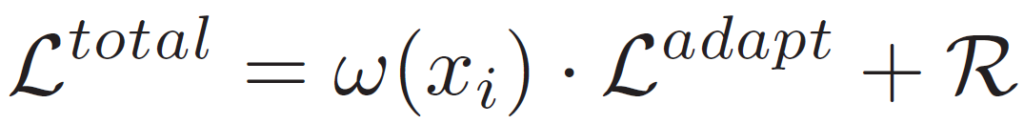
저자는 위 regularization term w 와 R을 통해 그림 1. (b)에서 설명드린, 이전에 adaptation을 수행해서 얻었던 지식(knowledge)을 잃게 되는 문제점을 해결할 수 있다고 합니다.
저자가 설계한 이상적인 그림으로 흘러간다면, 각 K개의 domain BN layers들이 비슷한 속도로 수렴이 일어나게 될 테니 말이죠.
3. Experiment
본 논문의 저자는 자신들이 설계한 TTA 모델의 효과를 classification과 semantic segmenation 분야에서 입증하였습니다.
3.1. Classification Experiments
Source domain 으로는 ImageNet dataset을, target domain으로는 ImageNet-C 라는 dataset을 사용하였습니다.
ImageNet-C는 기존 ImageNet에 15가지 corruption을 부여한 것으로 이에 대한 예시는 아래와 같습니다.
(그리고 아래 15가지 corruption은 비슷한 역할을 하는 녀석들끼리 noise, blur, weather, digital 이렇게 4개의 caterogy로 클러스터링 될 수 있습니다)

그리고 classification 모델로는 AugMix augmentation을 적용한 source dataset으로 사전학습한 ResNet-50을 사용하였습니다.
기존 CoTTA 라고 하는 논문의 evalutation 방식을 그대로 사용한,TTA 모델 평가 방식에 대해 알아봅시다.
아까 위에서 ImageNet에 15가지 corruption을 부여한 것이 ImageNet-C 라고 하였습니다. 그리고 이 15가지 corrupeted image를 어떤 순서로 배치하느냐에 따라서 시퀀스 를 정의할수 있게 됩니다.
사실 시퀀스의 전체 가짓수로 따지면 15! 의 가짓수가 나오겠지만, 10가지의 시퀀스만을 정의하였고 이에 대한 평균과 각 시퀀스들의 성능에 대해서 리포팅 하였다고 보시면 됩니다. 아래에 나오는 성능 표를 보시면 아마 이해가 원활하게 될겁니다.

우선 위의 표 1은 10가지 시퀀스의 평균 에러를 측정한 것입니다.
우선 평균 에러는 Ours 방식이 타 논문들에 비해 낮은것을 볼 수 있습니다.
그런데 Wall time이라고 하는, 시퀀스 1개에 대해 adaptation을 수행하는 데에 걸리는 시간을 보면 사실 CoTTA를 제외한 타 방법론들과 그렇게 차이가 나지 않네요.
제가 TENT, EATA 등 타 방법론에 대한 팔로업이 되지 않은 상태라 이에 대한 디테일한 비교를 못하는 점이 아쉽습니다.
다만 위 표에 표기되어 있지는 않지만, 기존 Domain Generalization 에서 사용하던 Kmeans clustering 기반의 매칭 방식과, 본 논문에서 설계한 continual domain-matching 기반의 매칭 방식의 소요 시간 차에 대한 언급을 하고있긴 합니다.
15개의 corruption중 단 하나의 corruption(약 5000개 sample로 구성) 에 adaptation이 완료되는데 까지 kmeans clustering 방식은 28분 16초(3fps), 본 논문의 방식은 32초(156 fps) 가 걸린다고 하네요.

또한 아래 표는 10가지 시퀀스 중 2가지 시퀀스를 골라서 각각에 대한 자세한 성능을 표기한 표 입니다.
선정한 시퀀스는 Continuous Sequence와 Random Sequence 인데, Continuous Seq은 15가지 corruption중 비슷한 corruption을 연속해서 등장시키는 방식입니다.
아까 위에서 ImageNet-C 에 대한 설명을 드릴 때 15가지 corruption을 비슷한 역할을 하는 것에 따라 noise, blur, weather, digital 이렇게 4가지 category로 나눌 수 있다고 했는데, 같은 catergory에 속하는 것들을 연속적으로 등장시켜서 시퀀스를 구성하는 것입니다. 위 표를 보시면 각 카테로리의 첫 알파벳이 대문자로 표시된것을 볼 수 있죠.
(Gaus.N, Snow W,,, 이렇게 말입니다)
그리고 두번째 시퀀스는 Random Seq 입니다. 말 그대로 랜덤하게 15가지 corruption을 배치한 것을 의미하죠.
본 논문에서는 물론 Continuous Seq에 대해서도 SOTA를 달성했지만, 그 보다도 Random Seq에 대한 성능 향상폭이 더 큰것을 볼 수 있습니다.
결국 저자가 설계한 TTA 모델을 통해 습득된 compound domain knowledge 모델링을 통해 random한 상황에 대해서도 강인하게 TTA가 수행이 되는것을 볼 수 있네요.
3.2. Semantic Segmentation Experiment
Source domain 으로는 {GTA-5, C-driving} dataset 을, target domain으로는 {CityScapes, Cityscapes with corruption} dataset을 사용하였습니다.
<source domain>
GTA-5 dataset은 비디오 게임을 통해 습득한, 합성(synthetic) 이미지로 구성된 dataset입니다.
그리고 CityScapes dataset은 대표적인 real-driving scene dataset입니다. clear weather에서 촬영되었죠.
<target domain>
C-Driving dataset은 real-world dataset이긴 합니다만 여러 noisy한 상황들로 구성되어 있습니다. weather의 특성에 따라 cloudy, rainy, snowy로 구성되어 있고, 시간대적 특성에 따라 day, twilight(황혼,해질녘), night 이렇게 말이죠.
그리고 CityScapes-C dataset은 위 Cityscapes 에다가 4가지 corruption을 부여해서 구성한 dataset입니다. 이에 대한 설명은 아래 그림을 보시면 명확히 이해되실겁니다.
아래 4개 중 Speckle noise는 sensor noise를 , brightness는 급격한 sun glare 변화를, 그리고 Contrast는 tunnel에 갑자기 들어가게 되는 상황을 나타내고자 부여한 corruption 입니다.

아래 실험 table에서는 2가지 실험을 진행하는데,
각각 GTA-5 dataset => C-Driving dataset 로의 adaptation, 그리고 CityScapes dataset => CityScapes-C dataset 로의 adaptation 성능을 리포팅하고 있습니다.
segmentation 수행 모델로는 adaptation 학습 기법들에서 많이 사용하는 segmentation계의 근본 논문인 ResNet-50 백본 기반의 DeepLabV3와 DeepLabV3+ 를 dataset에 따라 설정해서 사용하고 있습니다.
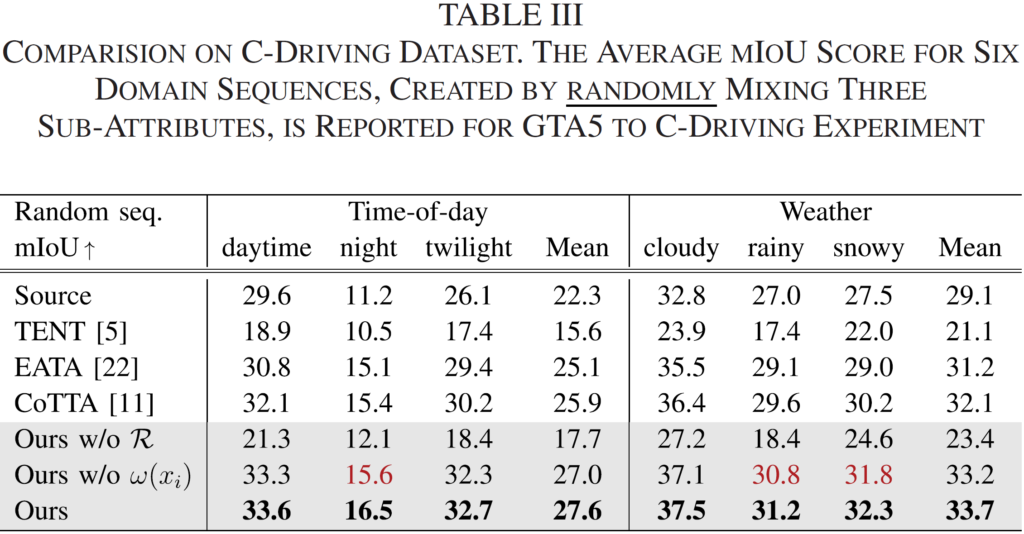
우선 위 표는 GTA-5 dataset 를 source로, C-Driving dataset 을 target으로 설정한 후 TTA 성능을 평가한 결과입니다.
위 dataset 설명 부에서 말씀드렸다시피 C-Driving dataset은 'Time-of-day', 그리고 'weather'에 따라 각각 3가지의 하위 속성이 존재합니다. 이를 각각 랜덤하게 혼합한 후에 성능을 평가한것입니다.
타 방법론들에 비한 성능 향상을 ablation 실험과 함께 보여주고 있습니다.
위 ablation을 보시면 $ R $ 과 $ w(x_i) $ 의 유무에 대한 성능 향상폭을 보여주고 있습니다.
$ R $ 은 제가 이해한 바로는 기존 방법론에서 사용된 regularization term을 그대로 가져와서 사용한 것입니다. $ R $ 의 적용 유무에 따른 성능 향상 gap이 어마무시하네요.
반대로 $ w(x_i) $ 는 본 논문에서 직접 설계한 regularization term 입니다. $ R $ 에 비해 향상폭은 많이 낮지만, 그래도 mIOU 기준 0.5라는 향상을 보여주고 있긴 하네요.
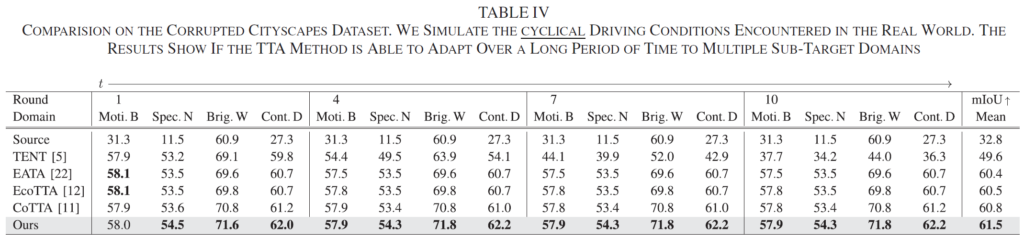
다음은 CityScapes dataset 을 source로, CityScapes-C dataset 를 target으로 설정한 후 TTA 성능을 평가한 결과입니다. CityScapes-C 구성 시 사용한 4가지의 corruption에 대해 각 round에 걸쳐 1, 4, 7, 10 round에서 성능 평가를 진행한 결과입니다.
Round의 정확한 정의에 대해선 적혀있지 않습니다만, 어쨋든 동일하게 주기적으로 n번 반복해서 n-round에서의 성능을 평가한 거 같네요.
이렇게 round 개념을 도입했을때 눈여겨 봐야할 점이 후반 round로 진행될 수록 성능이 계속 잘 유지되는지 입니다. 본 리뷰 상단부 그림 1.(b)를 보시면 결국 본 논문에서 저자가 언급한 기존 방법론들의 문제가 결국 오래 전에 습득한 지식(knowledge)을 잃어버린다는 것이였죠.
특히 위 표에서 TENT 방법론을 보시면 round가 뒤쪽으로 진행될 수록 큰 성능 하락을 겪는것을 볼 수 있습니다. 장기적인 long-term adaptation에 대한 overfitting 문제 해결을 고려하지 않았기 때문이죠.
반면 본 논문의 실험 결과는 장기적 round에서도 knowledge를 지속적으로 보유함으로써 성능이 유지되고, 성능 또한 타 방법론 대비 SOTA를 달성했습니다.
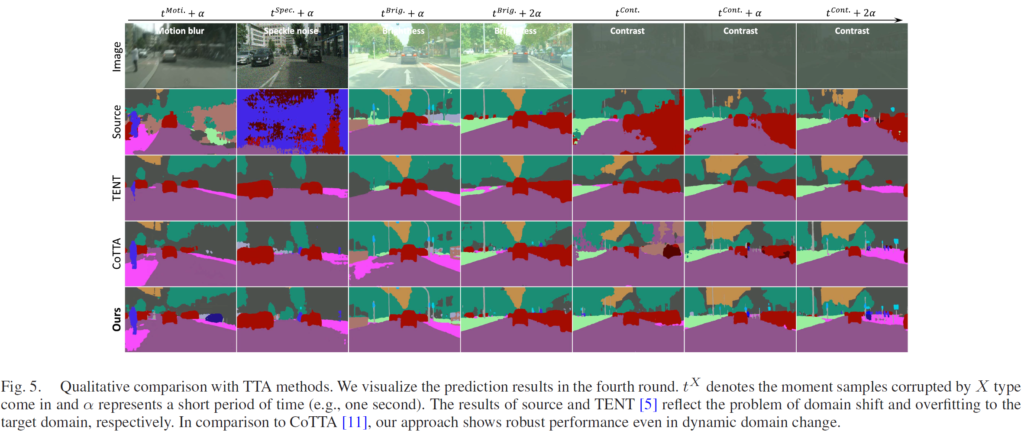
본 시각화 결과의 가로축이 시간의 변화라고 보시면 되고,
이 중 $ t^{Brig.}+2\alpha $ 에서 $ t^{Cont.} $ 로 domain이 넘어가는 상황을 초점으로 보시기 바랍니다. 비교군은 CoTTA와 Ours 입니다.
해당 시간 변화가 실제 상황이라면 마치 햇빛이 쨍쨍한 곳에서 갑자기 터널로 들어가는 시나리오인데요, $ t^{Cont.} $ 에서 Ours방법론에 비해 CoTTA가 우측 영역에서 매우 잘못된 예측을 하는것을 볼 수 있습니다.
저자는 이에 대해 바로 이전 domain (Brightness) 에 대해 강하게 최적화되어 있기 때문에 갑작스런 domain 변화에 잘 대응하지 못했다라고 설명합니다. 그에 반해 Ours는 정확한 예측을 수행했죠.
근데 사실 이 시각화 결과는 체리픽이긴 한게, 표 4의 성능에서 CoTTA와 Ours를 비교해보시면 mIOU가 0.7밖에 나질 않습니다. 그래도 뭐, 저자가 의도한 점이 시각화 결과에서 잘 표현되고 있다는 점이, 저자의 설계 방향대로 모델이 잘 adaptation 되었다는 것을 말해주기도 하네요.
3.3. Empirical Study

2.2.3. 절에서 설명드릴때 결국 본 논문에서 제안하는 domain prototype의 갯수 K는 사람이 직접 실험적으로 정의해야 한다고 말씀드렸습니다. 위 표는 그에 대한 ablation 결과이구요.
사실 생각보다 더 적은 수의 domain prototype 숫자라 놀랐습니다. 3 or 4네요.
ImageNet-C 에선 15개의 corruption이 존재하고, 이 때 최적의 K는 4,
C-driving 에선 총 6개의 특징이 존재하는데 이때 최적의 K는 3인것을 실험적으로 증명했습니다.
4. Conclusion
네 이렇게 제 첫 Test-Time Adaptation 분야의 리뷰가 끝났네요.
처음 다뤄보는 분야인지라 Introduction, method에서 이런저런 타 방법론들 설명을 추가할 수 밖에 없었고, 이 때문에 리뷰가 좀 길어진 거 같네요.
결국 본 논문에서는 기존 kmeans clustering 기반 domain matching은 시간이 너무 오래 걸린다는 단점을 언급하며 K개의 domain distinctive prototypes를 설계해서 continual domain matching을 진행하였습니다.
또한 이전 domain에서 배운 지식(knowledge)을 잘 보존하고, 오랜 시간 TTA를 진행했을 시 발생할 수 있는 overfitting을 해결하고자 새롭게 regularization term을 설계했구요.
사실 TTA 방법론의 베이스라인격 논문부터 차근차근 읽어온게 아니라 갑자기 쌩뚱맞게 2023년도 논문을 읽은 것이라 이전 방법론들에 대한 베이스 지식 부족으로 인해 이해하기 어려웠던 부분도 꽤나 존재했습니다.
아마 다음엔 TTA의 베이스라인 격 논문부터 리뷰를 차근차근 진행해 볼 예정이니 점점 더 TTA 분야의 베이스 지식이 쌓여갈 거 같습니다. 마치 본 논문에서 domain prototype이 continual하게 Moving Everage 방식으로 update해 나가는 거 처럼 말이죠.
그럼 오늘 리뷰는 이만 마치도록 하겠습니다.
긴 글이였을텐데 읽어주셔서 감사합니다.



