
안녕하세요.
오늘 리뷰할 논문은 2023년도 CVPR 2023에 투고된 따끈따끈한 논문입니다.
CVPR accepted paper list 를 살펴 보다가 제목에 제가 흥미로워 하는 키워드가 몇 가지 있어서 한번 읽어보게 되었습니다.
매번 리뷰하던 것 처럼 Semantic Segmentation 분야에 한정된 논문은 아니구요, 여러 visual task에 모두 적용 가능한 Unsupervised Domain Adaptation(UDA) 기법을 제안한 논문입니다.
++ 다 읽고 리뷰를 쓴 뒤에 돌아보니 문제 정의, 해결책, 실험 등이 매우 깔끔, 명료 하면서 효과 또한 확실한 좋은 논문이라는 생각이 드네요.
그럼 리뷰 시작하도록 하겠습니다.
1. Introduction
Masked Image Modeling (MIM)
본 논문을 포함해서 최근 연구가 많이 진행되고 있는 Masked Image Modeling(MIM) 은 입력 이미지를 random하게 마스킹하고, 마스킹된 영역을 reconstruct 함으로써 모델이 challenge한 환경에서 좀 더 강인하게 학습되도록 합니다.
마스킹된 영역을 reconstruction할 때 입력 RGB image를 reconstruction 하는지, 특정 feature 를 reconstruction 하는지에 따라서도 많은 논문들이 존재합니다. 대표적으로 Facebook AI Research(FAIR)에서 수행한, HOG feature를 reconstruction 하는 방법론이 존재합니다.
이 글을 읽고 계시는 독자분들께서는 Kaming He 님(?)의 '[CVPR 2022] Masked Autoencoders Are Scalable Vision Learners' 논문 리뷰와, 해당 논문에서 파생된 수많은 MAE(Masked Auto Encoder) 논문들을 한번쯤은 접해 보셨을 겁니다.
MAE와, 이에 파생된 연구들은 결국 input image를 랜덤하게 마스킹하고, 미리 정의한 pretext task(RGB, HOG,, reconstruction) 를 진행함으로써 모델의 feature extraction 성능을 향상시키고 이를 downstream task에 적용하는 SSL(Self-Supervised Learning) 을 수행하지요.
본 논문은 input image를 랜덤하게 마스킹하는 점에서 공통점이 있지만, self-supervised representation을 학습하는 것이 아닌, 기존 unsupervised domain adaptation (source=>target) 상황에서의 문제점을 정의하고 이를 해결하기 위해 source dataset의 context relation을 최대한 target에 전달하도록 Masked Image Modeling(MIM) 기법을 설계합니다.
제 필력이 부족하여 잘 와닿으실지 모르겠지만,,, 계속해서 추가적인 설명 진행해 보겠습니다.
Unsupervised Domain Adaptation (UDA)
우선, 본 논문은 결국 Unsupervised Domain Adaptation(이하 UDA) 분야에서의 문제 정의와 해결책을 제시하였기 때문에 UDA task에 대한 간단한 이해는 필수적이라 생각됩니다. 아래 단락에서 UDA에 대한 설명, 그리고 현 UDA 연구에 대한 저자의 문제정의와 해결 방안에 대해 설명드리겠습니다.
Semantic Segmentation, Image Classification, Object Detection 등 여러 Visual Recognition Task 연구에서 가장 중요한 요소들 중 하나는 무엇일까요? 바로 large-scale의 annotated dataset 입니다. large-scale annotated dataset의 부재로 인해 Self-Supervised 의 연구가 활발히 진행되고 있긴 합니다만 결국 여러 Visual Recognition Task 에서 모델의 성능을 대폭 끌어올리기 위해선 결국 large-scale annotated dataset이 필요한 상황이죠.
하지만 우리가 알다시피 dataset을 모으고 annotation하는 과정은 매우 시간적, 비용적으로 비싸죠. 예시로 annotation 난이도가 극악(?)이라고 알려진 Semantic Segmentation의 경우 한 장의 이미지를 annotation 하는데에 평균 1시간이 소요된다고 합니다.....ㅎ
그래서 상대적으로 annotation이 쉬운 시뮬레이션 데이터(simulated datasets)을 사용해서 모델을 학습하는 연구들도 존재합니다. 대표적으로 GTA dataset(아래 그림 참조) 이 있는데 이는 우리가 흔히 benchmarking하는 dataset에 비해 annotation의 난이도가 낮아서 large-scale의 annotated dataset 구성이 상대적으로 쉽다고 합니다. (annotation 과정을 몰라서 왜 상대적으로 쉬운지는 잘 모르겠네요,,ㅎ)
아무튼 이런 데이터셋을 보통 Synthetic Dataset이라고 부르기도 하고, GTA dataset는 무려 24,966 장의 Semantic Segmentation annotated image가 존재한다고 하네요. (엄청 큰 규모입니다,.!)

하지만 이런 Synthetic Dataset의 경우 뭔가 우리가 아는 real scene이랑은 조금 다르죠?
large-scale의 annotated synthetic dataset으로 학습된 모델을 CityScapes, KAIST 등의 real-world dataset에 바로 적용하게 되면 둘 사이의 domain gap으로 인해 모델의 성능이 확 떨어지곤 합니다.
그래서 이런 큰 규모의 source annotated dataset(ex. GTA Dataset)에서 학습한 훌륭한 정보들을 최대한 domain gap을 해결하면서 작은 규모의 target dataset에 잘 전달하는 것을 연구하는 분야가 Domain Adaptation이고, target domain dataset에 gt label을 사용하지 않는 경우 이를 UDA(Unsupervised Domain Adaptation) 이라고 합니다.
UDA를 수행하는 앞선 연구들은 아주 크게 2가지로 구분됩니다. 첫번째는 adversarial training 방식이고, 두번째는 self-training 방식입니다.
- adversarial training 방식의 경우 GAN모델에서 제안된 discriminator를 사용합니다. 여기서 메인 모델은 generator 역할을 하여 source domain feature와 target domain feature를 최대한 비슷하게(?) 만들어내고, discriminator는 이를 최대한 구별하는 방향으로 학습이 진행되면서 상대적인 domain gap이 줄어드는 효과를 볼 수 있죠.
- 그리고 self-training 방식의 경우 특정 confidence threshold등의 제약을 적용해서 target domain를 위한 pseudo label을 생성하게 됩니다. 특정 제약을 설정해서 이를 만족하는 데이터만을 활용해 점차적으로 domain adaptation 이 수행되게 됩니다.
두 방식에 대해 좀 더 자세하게 설명드릴 법도 한데 간단하게 설명드린 이유가 있습니다. 본 논문은 두 가지 방식 중 하나를 통해 UDA를 수행하는 것이 아니라, 기존의 UDA 방법론들에 합쳐서 함께 적용할 수 있는 새로운 모듈을 설계한 것입니다. 그렇기에 실험 부분에서도 기존 UDA 방식에다가 본 논문에서 새롭게 설계한 모듈을 추가해서 성능을 리포팅합니다.
Masked Image Consistency (MIC) Module
본 논문은 기존 UDA 방법론들의 문제점에 대해 언급하고 MIC 라는 새로운 모듈을 제안합니다.
아래 그림이 이를 잘 나타내 주고 있습니다.
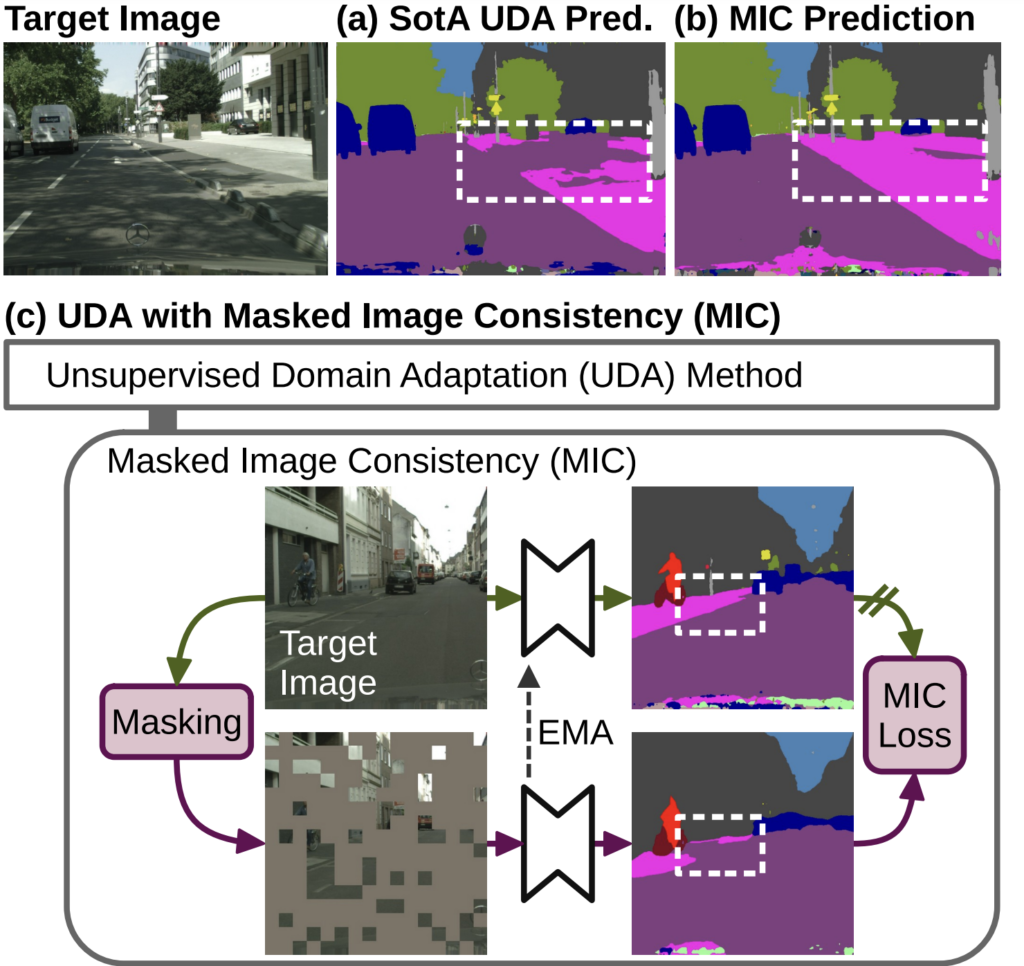
본 논문에서는 기존 UDA 논문들이 source dataset과 target dataset의 domain gap을 어느정도 해결했다고 말을 하면서도 반대로는 아직 supervised 학습 방식과는 성능 gap이 존재한다고 말합니다.
(Domain Gap을 완벽하게 해결했다면, upper bound인 Supervised 에 수렴하는 성능을 보이겠죠)
이 같은 문제에 대해 저자는 비슷한 시각적 특징을 가진 클래스들(road/sidewalk, pedestrian/rider) 끼리 매우 구별하기 어렵다고 합니다. 이는 말로 설명하기 보단 위 그림을 보고 이해하는것이 직빵입니다.
위 그림 상단의 Target Image(RGB)와 기존 UDA sota 방식의 예측 (a), 그리고 본 논문의 예측 (b)를 비교해 봅시다.
좌측 Target Image의 도로(road)와 인도(sidewalk)를 잘 보시면 사람이 봤을때에도 구별이 명확하지 않을 정도로 매우 비슷한 시각적인 특징을 지닌 것을 볼 수 있습니다.
이렇게 class는 다르지만, 비슷한 시각적 특징을 가진 경우 모델은 학습을 매우 어려워합니다. 이는 본 논문에서 수행하는 task가 unsupervised 상황이기 때문이죠. 만약 그냥 supervised 방식으로 학습을 한다라고 가정한다면, 물론 시각적인 정보가 유사하긴 하지만 gt로 주어지는 class의 label이 확연히 다르기 때문에 모델은 학습을 할 수 있습니다.
하지만 UDA에서는 target domain에 대해 학습할 때 target dataset의 gt를 사용하지 않습니다. 즉 주어지는 이미지의 시각적인 정보만을 가지고 많은 class들을 픽셀 단위로 구분해야 하는데, 여기서 시각적 정보가 유사해버리니 학습이 매우 어려워 지는 것이지요.
이를 해결하기 위해 저자는 Masked Image Consistency (MIC) 모듈을 설계하였고, 이는 기존 UDA 방식에 plug-in 방식으로 탈착이 가능한 모듈 형태입니다.
음,, 계속해서 설명하려 했으나 Introduction에서 너무 많은 내용을 다룬 거 같기에 MIC 모듈에 대한 구체적인 설명은 Method 단락에서 계속 진행하도록 하겠습니다.
2. Method
2.1 Unsupervised Domain Adaptation
UDA 방법론에서의 loss는 크게 2가지 term으로 나눠집니다.
첫번째는 source domain의 예측과 labeled source dataset 사이의 supervised loss를 통해 source domain에 대해 학습을 잘 수행토록 하는 loss 입니다.
그리고 두번째는 soucre domain과 target domain 사이의 performance drop을 최소화 하기 위한 loss 입니다.
이는 앞선 많은 UDA 연구들에서 adversarial 방식을 적용했는지, Self-Training을 적용했는지에 따라 달라지게 됩니다.
기본 base가 되는 방식에 따라 loss가 달라지기에 저자는 크게 묶어서 아래처럼 loss식을 정의했습니다.
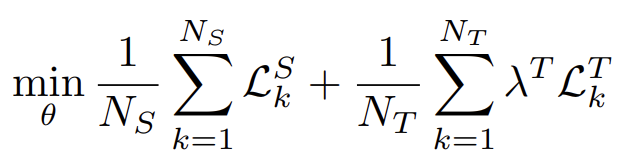
앞쪽 term인 $L^S_k $ 는 source domain에 대한 loss이고,
뒤쪽 term인 $ L^T_k $ 은 target domain 에 대한 loss 입니다.
본 논문에서는 segmentation, classification 등 여러 vision task의 UDA에 모두 적용 가능한 모듈을 설계하고자 했기에 $L^S_k $ 는 본 논문이 어떤 task를 수행하는지에 따라 달라지게 됩니다.
(본 단락은 2.2에서 설명드릴 MIC를 위한 preliminary 정도로 생각하시면 될 거 같습니다.)
2.2 Masked Image Consistency (MIC)
모델이 이미지 내의 물체를 인지할때는 크게 2가지 정보를 사용하게 됩니다.
첫번째는 동일한 patch(kernel)에서 뽑아낼 수 있는 지역적인(local) 정보이고,
두번째는 주변의 patch(kernel)에서 뽑아낼 수 있는 문맥적인(context) 정보입니다.
많은 SOTA 모델들은 위의 local 정보와 context 정보를 모두 고려하는 구조 가지죠.
이 두가지 정보 중에서 context 정보에 조금 초점을 둬 봅시다.
UDA의 source domain 에서는 gt를 사용하여 학습을 진행하기 때문에 local & context 정보를 모두 잘 학습할 수 있게 됩니다. 하지만 target domain의 경우는 학습 시 gt를 사용하지 않게 됩니다.
위의 그림 2-(a)를 보면 UDA의 문제점을 context 정보의 관점으로 바라볼 수 있게 됩니다.
(a)의 경우 도로와 인도를 잘 구분하지 못한 것을 볼 수 있는데, 이는 UDA 시 넓은 영역에 대한 context 정보를 충분히 학습하지 못했다는 것으로 볼 수 있습니다.
시각적으로 비슷한 특징을 지닌 class일 지라도, context 정보를 충분히 학습했다면 어떤것이 도로이고 어떤것이 인도인지 잘 구별할 수 있을텐데, 그러지 못한 것을 볼 수 있죠.
저자는 이 점을 문제로 정의하게 됩니다.
그리고 UDA 시 target domain이 context 정보를 잘 학습할 수 있도록 추가적인 기법을 설계하게 되죠.
해당 모듈은 Masked Image Consistency(MIC) 라 불리고, 타 UDA 방식에 plug-in 방식으로 적용했다 뺐다 할 수 있는 구조입니다.
MIC 모듈을 통해 저자가 얻고자 하는 효과는 위에서 설명 드렸다시피 target domain이 context 정보를 잘 학습하도록 하는 것입니다. 저자는 이를 달성하기 위해 target domain image에 Random Masking을 적용해서 local 정보를 억제해버립니다.
local과 context 정보 중 masking을 통해 local 정보를 억제해(지워) 버림으로써 모델이 context 정보만을 통해 잘 예측하도록 합니다. 이 과정에서 context 정보를 잘 학습하게 될 수 있다고 하네요.
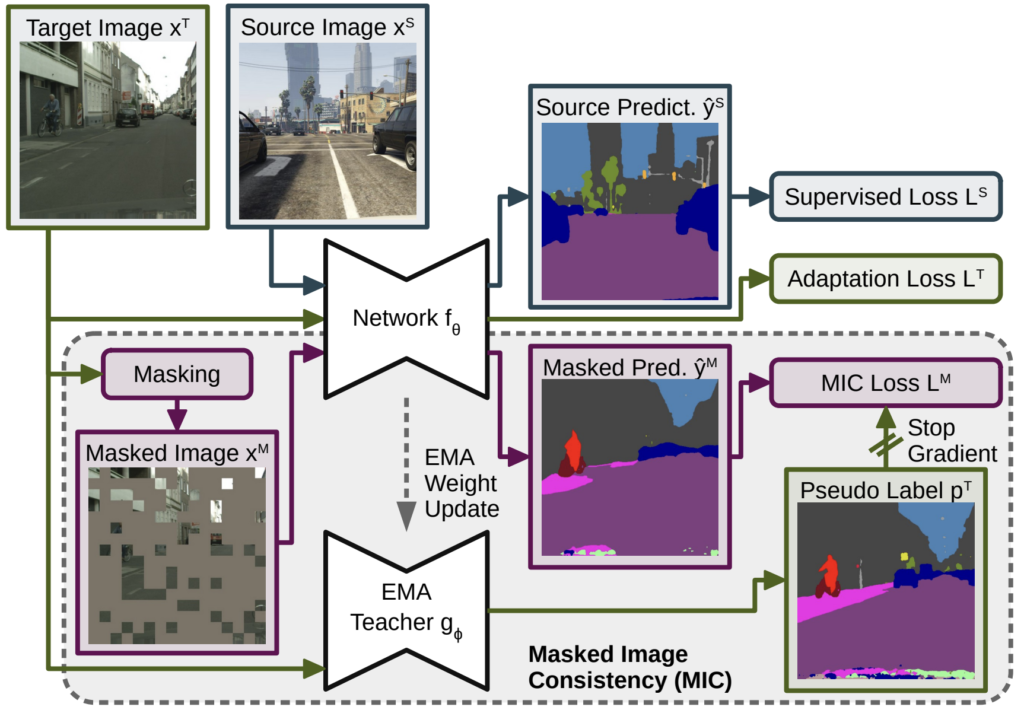
해당 모듈을 적용한 전체 구조는 아래와 같습니다.
Random Masking을 진행하는 mask M 경우는 아래 식을 통해 만들어집니다.
그냥 random하게 0 or 1의 값을 가지도록 하는 것입니다.
( [.] 는 Iverson bracket이라고 일컫는데, 해당 명제가 참이면 1 거짓이면 0을 반환합니다)

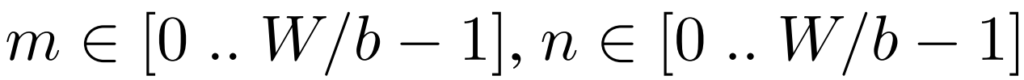
b는 batch size, r은 mask ratio, m과n은 patch의 indices를 의미합니다.
그리고 아래 식을 통해 원본 target image에 mask를 씌운 masked image $ X_M $ 을 생성하게 되죠. 아래 식의 연산자는 element-wise multiplication 입니다.

그리고 이렇게 masking된 target image는 제한된 정보만을 가지고 예측을 수행하게 됩니다.
아래 식은 그냥 masked target image를 통해 예측을 수행하는 식이, 위 그림 3에서 보시다시피 모델 $ f_\theta $ 는 source와 target이 공유합니다.

하지만 그림 3에서 masked target image를 통해 예측한 결과를 보시게되면 핑크색 인도(sidewalk) 영역의 예측이 잘못된 것을 알 수 있습니다. 아무래도 masking된, 정보가 제한적인 상황이다 보니 예측이 어려울 수 있죠.
저자는 이렇게 masking된 상황에서도 나머지 masking 되지 않은 context 정보를 통해 예측을 수행하고자 하였고, 이를 위해 아래에 보이는 것 처럼 MIC loss를 설계하였습니다.
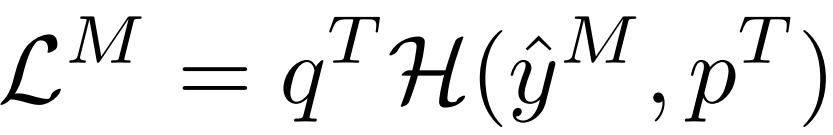
위 식에서 $ p^T $ 는 그림 3에서 보시다시피 EMA Teacher 가 예측해 낸 pseudo label 입니다. 이는 아래에서 추가 설명 드리겠습니다.
그리고, $ q^T $ 는 quality weight라고 불리는데, 이는 어떤 vision task (classification, segmentation)을 수행하는지에 따라 다르게 계산되는 값입니다.
그리고 대문자 H 처럼 생긴 녀석은 그냥 각 vision task 에 맞는 loss를 세팅하겠다는 것입니다.
정리하면, 위의 MIC loss는 그냥 pseudo label과, masked target image를 사용한 예측 끼리의 loss를 계산하겠단 겁니다. 어떤 loss를 적용할지는 task에 따라 달라지는 것이고, 그럼 여기서 중요한 건 위에서 한번 언급드린 EMA Teacher와 이를 통해 예측한 pseudo label 이겠네요.
사실 EMA 라는 개념은 '[NeurIPS 2017] Weight-averaged consistency targets improve semi-supervised deep learning results' 라는 논문에서 처음 제안된 개념입니다. 해당 논문은 글을 쓰고있는 현 시점을 기준으로 3434 의 인용수를 가지는 논문이네요.
저자는 위 그림 3에서 보시다시피 source image와 target image를 함께 입력으로 받는 network $ f_\theta $ 외에도 EMA Teacher network $ g_\phi $ 를 새롭게 도입합니다.
$ g_\phi $ 는 $ f_\theta $ 와는 다르게 masking 되지 않은 원본 target image를 입력으로 받고 예측을 수행하게 됩니다. 이 말은 $ g_\phi $ 의 경우 이미지의 local한 정보와 context 정보를 모두 보고 학습할 수 있다는 것이고, $ g_\phi $ 의 예측 또한 해당 정보들을 모두 반영하게 됩니다.
그리고 그림 3을 보시면 $ g_\phi $ 는 $ f_\theta $ 를 기반으로 하여 EMA 방식으로 update가 됩니다.
학습이 진행됨에 따라 점차적으로 $ f_\theta $ 는 context 정보 학습 능력을 가지기 때문에, 이러한 정보들이 $ g_\phi $ 로도 전달되면서 $ g_\phi $ 는 점차적으로 더 높은 성능의 예측을 수행할 수 있게 되는것입니다. 그렇기 때문에 $ g_\phi $ 의 예측을 pseudo label로 세팅하여 MIC loss를 계산하는 것입니다.
$ g_\phi $ 가 parameter를 update하는 방식은 아래 식을 통해 이루어집니다.
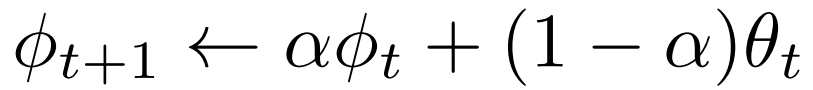
$ \alpha $ 는 smoothing parameter 로 vision task 에 따라 조금씩 다르게 세팅되지만 보통 0.9~0.999 정도로 세팅됩니다. 그리고 t는 training step(iteration) 을 의미합니다.
즉, 위의 식을 말로 풀어보자면 EMA Teacher network $ g_\phi $ 의 weight $ \phi $ 는 다음 step (t+1)의 weight를 설정할 때 현 step (t) 의 $ \phi $ 에다가 현 step의 Network $ f_\theta $ 의 weight $ \theta $ 를 조금 반영하여 update 한다는 것입니다.
부가적으로 그림 3에 MIC Loss 계산 부분에서 pseudo label이 전달될 때 stop gradient 인 것으로 보아 해당 loss를 통해서는 $ f_\theta $ 만 학습이 진행되면서 weight 가 update 되고, Mean Teacher $ g_\phi $ 의 weight는 backward 과정이 아닌, EMA Weight Update 과정을 통해서만 update 되는것을 알 수 있네요.
이렇게 MIC loss를 설계하여 적용한 본 학습 기법의 최종 loss는 아래 식과 같습니다.

2.1 단락의 UDA 설명에서 언급드린 loss에다가 MIC loss만 추가적으로 더해진 것을 알 수 있습니다.
Method 단락을 마무리 하기 전에 조금 정리해 보자면 저자는 기존 UDA 방식들이 비슷한 시각적 정보를 지닌 서로 다른 class 구분을 잘 못한다는 점을 언급하며 context(문맥) 정보를 잘 학습하기 위한 추가적인 기법이 필요하다고 주장하였습니다.
그리고 이를 위해 target domain image에 random masking을 적용하여 local(지역) 정보를 억제해버림으로써 오히려 context 정보만을 통해 잘 예측해봐라~ 라는 기대효과로 masking 기법을 적용하였습니다.
하지만 아무래도 masking을 할 경우 정보의 양이 줄어들기 때문에 이렇게 제한된 상황에서도 마찬가지로 예측이 잘 수행되지 않았고, 이를 해결하고자 Mean Teacher 기법을 도입하여 pseudo label을 생성하고 이와의 loss를 설계하였습니다.
결론적으로 target domain 에서도 context 정보까지 잘 반영된 성공적인 예측을 수행할 수 있게 되었습니다.
3. Experiment
저자는 여러 상황에 대해 UDA를 수행하였습니다. 그래서 Dataset의 종류도 꽤나 많습니다.
각 vision task별로 사용된 dataset과, 이에 대한 실험 결과에 대해 나눠서 설명 드리겠습니다.
저자가 Segmentation에 대해 중점적으로 실험하기도 했고, 제가 연구하고 있는 분야도 Segmentation인지라 타 task에 대한 실험 결과가 조금 허접(?)해도 양해 부탁드립니다...ㅎㅎ
Semantic Segmentation
Semantic Segmentation 에서는 3가지 상황으로 나눠서 UDA 를 실험하였습니다.
우선 'Synthetic-to-real' 상황입니다.
합성 데이터 => real-world 데이터로의 adaptation을 평가한 것이고, 합성 데이터로는 24,966장의 GTA Dataset과 9,400장의 Synthia Dataset을 사용하였습니다. 그리고 real-world 데이터셋으로는 3,475 장의 CityScapes Dataset을 사용하였습니다.
그리고 'Clear-to-adverse-weather' 상황에 대해서도 실험을 설계하였습니다.
Claer 상황에서는 CityScapes Dataset을, adverse-weather 상황에는 fog,night,rain,snow 등의 상황을 가지는 총 4,060장의 이미지로 구성된 ACDC Dataset 을 사용하였다고 합니다.
마지막으로 day-to-nighttime 으로의 상황입니다.
Day time은 마찬가지로 CityScapes를 사용하였고, Nighttime은 2,567장으로 구성된 DarkZurich Dataset을 사용하였습니다.
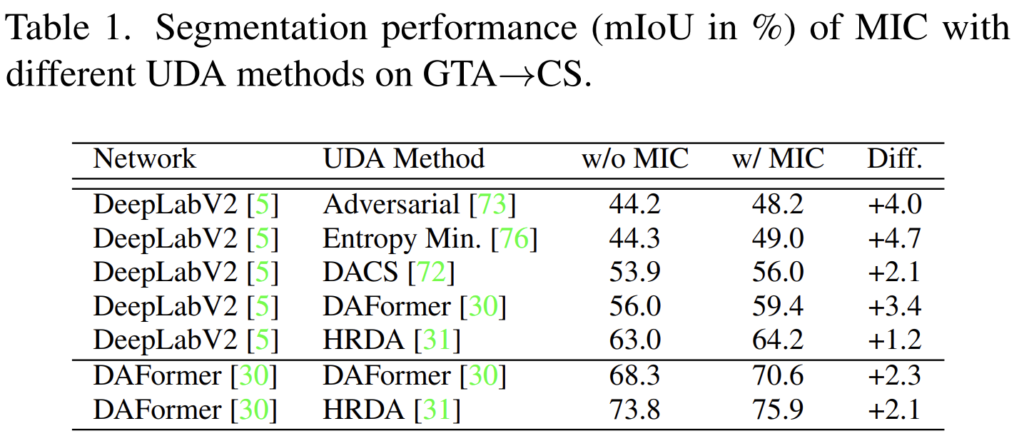
우선 합성데이터->real 데이터 상황에서의 Semantic Segmentation 실험입니다.
데이터셋은 GTA와 CityScapes를 사용하였네요.
기존 Adversarial, HRDA 등의 UDA 방법론들에 본 저자가 설계한 MIC를 도입했을때의 성능 향상 폭(Diff.) 를 잘 보여주고 있는 table 입니다. 다들 성능향상폭이 꽤나 인상적인데, 여기서 주목할 점은 CNN 기반의 DeepLabV2 모델 뿐만 아니라, Transformer 기반의 DAFormer에서도 성능 향상을 이루어 내었다는 점입니다. 모델 연산 종류에 국한되지 않고 보편적으로 적용 가능한 기법임을 보여주고 있네요.

그리고 위에서 제가 소개드린 3가지 상황 모두에 대한, Semantic Segmenation 성능 결과입니다.
기존 UDA 기법 HRDA의 성능과, 이에 본 논문의 기법을 적용한 MIC(HRDA) 와의 성능 향상 폭에 대해 초점을 잡고 보겠습니다. 우선 거의 모든 class에 대해서 성능 향상이 일어났네요. 저자가 문제정의 한 road와 sidewalk(S.walk)에 대한 향상폭을 보면 특히 sidewalk 에서의 향상폭이 특히 인상적이네요.
그리고 sidewalk, fence, pole, traffic sign, terrain, and rider 등 처럼 기존 방법론에서 성능이 그렇게 높지 않았던 class에서 꽤나 큰 폭의 향상을 보여주고 있는것을 볼 수 있습니다. 기존 UDA에서 꽤나 어려워 했던 context 정보 학습에 대한 문제점들을 해결하였다고 볼 수 있겠네요.
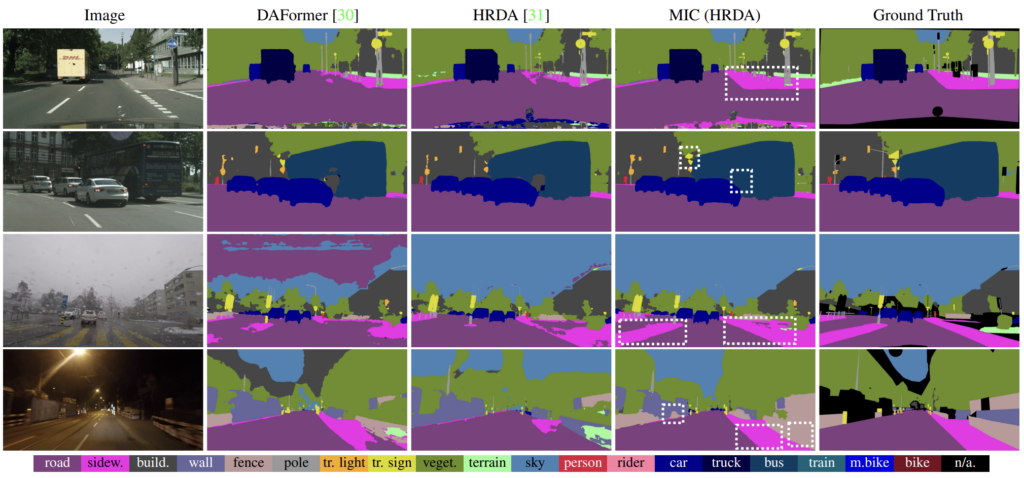
그리고 정성적 결과에 대해서도 살펴보겠습니다.
그림에서 하얀 점선으로 네모 박스가 그려진 영역에 대해서 집중적으로 비교해서 보시면 됩니다.
확실히 문맥(context) 정보가 중요한 부분들에 대해서 훨씬 더 성능높은 예측을 하는것이 확연히 보이네요.
Image Classification
그 다음은 Classification 입니다.
12개 클래스 280,000 장의 합성+real 이미지로 구성된 VisDA-2017 Dataset과,
65개 클래스 15,500 장, 그리고 각각 art (A), clipart (C), product (P) and real-world (R) 의 도메인으로 구성된 Office-Home Dataset을 사용했다고 합니다.

거의 모든 class에 대해 성능 향상이 일어 났네요!

또한, 타 방법론들이 어려워 하는 A->C 와 P->C 에 대한 성능 향상폭이 정말 인상적이네요. 각각 10, 5 의 향상입니다. 이를 통해 저자들이 제안한 MIC Module이 정말 타 방법론들의 문제를 잘 해결해 줬다고 생각드이 듭니다.
Object Detection
Detection 에서는 CityScapes->Foggy CityScapes 로의 실험을 진행합니다. 결과는 아래와 같습니다.
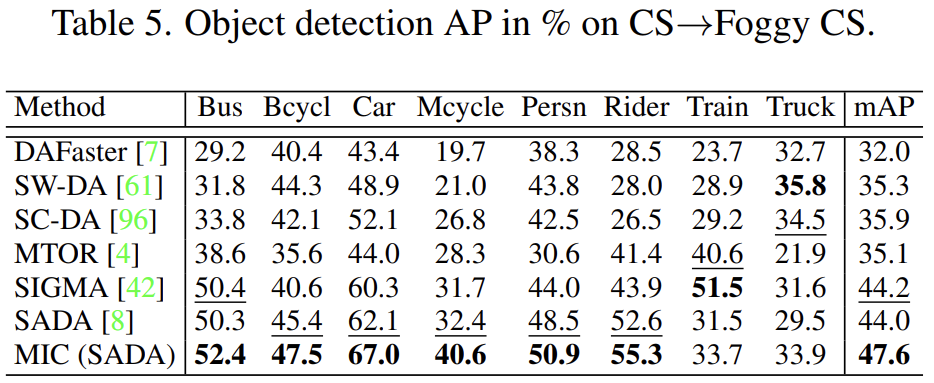
특히 SADA 기법론에서 성능이 낮은 Mcycle에 대해 성능 향상폭이 꽤나 크네요.
Ablation Study
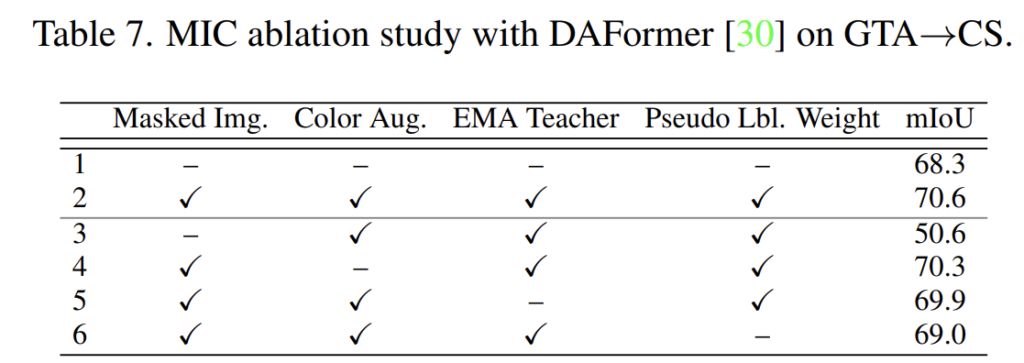
각 기법에 대한 Ablation 입니다.
위 표에서 3번을 보시면 Masking 기법을 제외하고 나머지는 다 적용한 경우인데, 이 경우엔 모두 적용한 것 대비 20mIOU나 성능이 떨어지네요,..

다음은 Patch size b와 masking 비율에 대한 ablation study 입니다.
b=64 및 r=0.7 에서 제일 높은 성능을 보여주고 있습니다.
제가 위에서 설명드릴때 image에 masking을 함으로써 local 정보를 억제한다고 말씀 드렸었습니다.
그렇기 때문에 전 patch의 size가 꽤나 작을 것이라 생각을 했었습니다. (local은 보통 좁은 영역을 칭하기 때문)
하지만 제일 높은 성능을 보이는 patch size b가 64인 점을 보면 꽤나 놀랍네요..
4. Conclusion
네, 이렇게 CVPR 2023 논문을 처음 읽어보게 되었습니다.
마지막에 실험 파트의 ablation에서 제가 다루지 못한 것들이 몇가지 더 있는데 시간문제 상 리뷰에 담지 못한 점이 너무 아쉽네요...ㅎ
읽으면서 확실히 CVPR 논문은 다르다,, 생각이 들었습니다.
문제정의도 확실하고, 이를 해결하기 위한 contribution도 매우 간단명료 하면서 여러 vision task에 적용한 실험까지. 심지어 글의 흐름도 매우 좋아서 읽기에 군더더기가 없었습니다.
그리고 Image를 local과 context 정보로 나눠서 생각했을 때 본 논문에서는 context 정보를 잘 학습하고자 하였습니다. 여기서 context 정보를 잘 학습하고자 오히려 반대로 local 정보를 억제해버림으로써 이를 쟁취한 점도 꽤나 신선한 접근이였던 거 같습니다.
(사실 patch size b=64에서 64가 local인 거 치곤 좀 크다는 생각이 들긴 하지만,.,... 저자가 local 정보를 억제한다고 표현하더라구요)
아무튼 오랜만에 좋은 논문을 읽은 거 같네요.
다들 읽어주셔서 감사합니다!



