
안녕하세요,
오늘도 늘 먹던 분야의 논문을 가지고 왔습니다.
다만 KBS 라고 하는 저널은 많은 분들이 처음 보실거라 생각이 드는데요,
이는 Knowledge Based System (KBS) 라고 하는 저널입니다.
Impact Factor가 8 이상으로 꽤나 높은 Q1 급의 저널입니다.
뭐 아무튼, 해당 논문에 투고된 DA 논문 리뷰를 시작하도록 하겠습니다.
1. Introduction
사실 Domain Adaptation 기법으로 Semantic Segmentation task를 수행하는 논문을 많이 리뷰하였고,
이 글들의 초반부 내용들은 대부분 유사합니다.
annotation cost가 매우 크고, 그렇기 때문에 큰 규모의 labeled sourcedataset으로 부터 정보를 받아와 unlabeled target dataset의 성능을 최대치로 끌어올리는 것이 DA의 목적이고, 이때 source domain과 target domain 사이의 domain gap(discrepancy)를 줄이는 것이 핵심 포인트가 되겠죠.
앞선 많은 DA 방식들은 mapping 에 의존하게 됩니다.
다시 말해 feature level에서 source domain의 feature를 target domain으로 최대한 유사하게 mapping 함으로써 둘 사이의 domain shift를 최소화 하는것이죠.
성공적으로 domain shift를 최소화 했을 때 source dataset으로 학습 된 모델이 target dataset에서도 잘 동작하리라 하는 기대로 mapping 을 수행하게 되는것입니다.
그리고 여기서 보통의 방식들은 adversarial 방식을 채택해서 source domain에서 target domain으로 feature의 분포를 맞추게 됩니다.
비록 앞서 설명드린 feature mapping 방식을 통해 source와 target 사이에 존재하던 domain gap을 어느정도 잘 해결하긴 하였지만, 저자는 여기서 신박한 관점의 문제를 정의하게 됩니다.
feature mapping을 통해 DA를 수행하는 알고리즘(algorithm) 과 사람(human) 사이에는 근본적인 차이가 있다는 것이죠.
신경망 모델(알고리즘,algorithm)은 새로운 domain에 적응(adapt)할 때 feature mapping을 통해 수행했지만,
사람은 기존에 살던 곳과 다른 환경(environment, domain)에 적응할 때 feature mapping이 아니라 knowledge(지식) 을 사용한다는 뜻입니다.
조금 더 자세하게 살펴봅시다.
사람은 살고 있는 주변 상황을 knowledge(지식) 으로 학습하고, 이를 사람의 인식체계에 저장하게 됩니다.
이렇게 저장된 knowledge는 A가 아닌 B, C 등 새로운 장소(domain) 에 가던 동일하게 유지되고, 그대로 사용되겠죠.
저자는 사람(human)의 이런 적응-인식 체계에 영감을 받아서 새로운 domain에 가도 동일하게 유지되는,
즉 source와 target에 무관한 공통 지식(common knowledge) 개념을 제시하게 됩니다.
source와 target에 무관하게 공통되는 지식을 사용함으로써 source to target adaptation을 더 성공적으로 수행하고자 하는 것입니다.
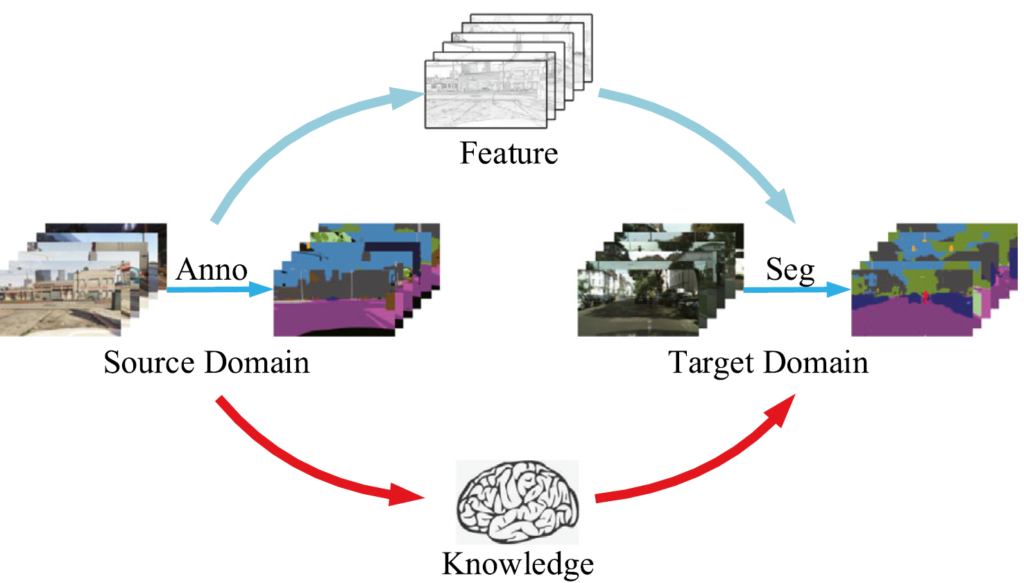
앞서 설명드린 공통 지식(common knowledge) 라는 개념을 나타낸 것이 위 그림입니다.
사실 중요한 내용이 내포되어 있는것은 아니고, 기존 DA 에서는 위 하늘색 화살표가 나타내는 Feature mapping 기반 adaptation을 수행했다면, 본 논문에서는 아래의 빨간색 화살표가 나타내는 knowledge 기반 adaptation을 수행하겠다~ 뭐 이런 뜻입니다.
본 논문에서는 knowledge 라는 개념을 semantic classes에 대한 descriptions로 사용하게 됩니다.
말이 조금 어려울 수도 있는데, 각 class에 해당하는 text로 부터 추출된 embedding vector를 knowledge 라고 칭하는 것입니다.
이에 대한 설명과, 본 논문의 전체 동작 과정에 대해선 아래 method에서 자세하게 설명드리도록 하겠습니다.
2. Method
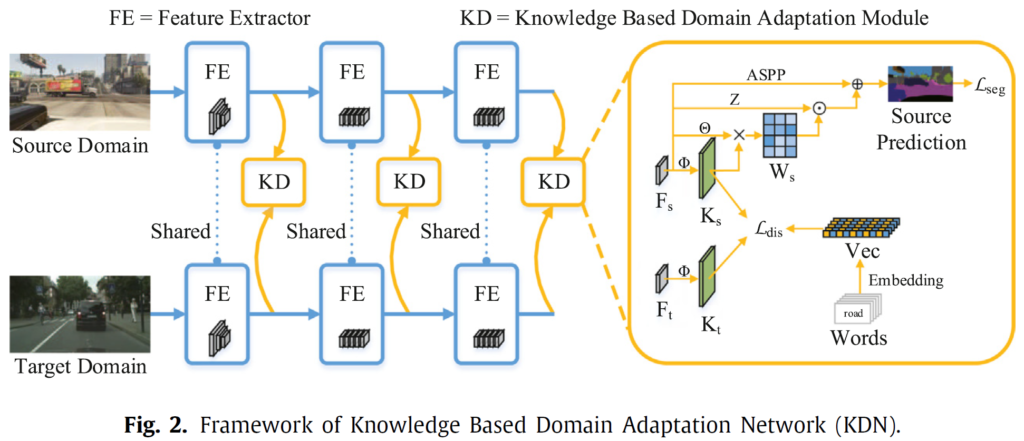
위 파이프 라인이 본 논문에서 제안하는 전체 architecture 이며, Knowledge Based Domain Adaptation Network (KDN) 이라고 불립니다.
그리고 이는 Feature Extractor (FE) 와, Knowledge based Domain Adaptation module (KD) 로 구성됩니다.
사실 FE 는 그냥 feature를 추출하는 단계입니다.
Deeplab V2 라고 하는 유명한 CNN 기반의 segmentation network를 사용하게 되는데, 해당 network를 3 단계로 나눠서 중간 중간에 KD 모듈이 도입된 것을 볼 수 있네요.
자세히 보면, 첫 번째 FE 모듈은 resolution이 점점 감소하는 흔한 encoder 형태이지만, 두 번째와 세 번째 FE 모듈은 resolution이 그대로 유지되는 것을 볼 수가 있습니다.
이는 Deeplab V2 모델의 특성 때문인데요, 성공적인 segmentation 예측을 수행하기 위해서 위치 정보를 그대로 보존하길 바랬던 Deeplab V2의 저자들은 encoder 단계에서 1/8 (혹은 1/16) 이상으로 resolution 이 감소되지 않도록 ASPP (Atrous Spatial Pyramid Pooling) 를 설계하였습니다.
사실 본 리뷰가 Deeplab V2 리뷰는 아닌지라 자세한 설명은 생략하고,
본 논문의 핵심은 KD 모듈의 설계 기법에 있습니다.
그리고 이는 아래 3가지 단계로 구성되어 있습니다.
- Knowledge loading
각 source domain과 target domain에서 추출된 high level feature로 부터 common knowledge 를 load 한 뒤,
설계한 triangular constraint를 통해 align을 맞춰 나가는 과정. - Knowledge filtration
앞서 load된 knowledge를 weight matrix에 embedding 시킴으로써 특정 입력 scene에 따라 filtering 하는 과정. - Knowledge fusion
위 단계에서 filtering된 knowledge가 원본 image feature와 합쳐짐으로써 DA가 수행되는 단계.
이때 앞서 구한 weight matrix가 사용됨.
네, 이런 간단한 설명으로 이해하기 쉽지 않으실겁니다.
이해하기 수월하도록 자세한 설명들은 아래 2.1. 부터 진행하겠습니다.
2.1. Knowledge loading
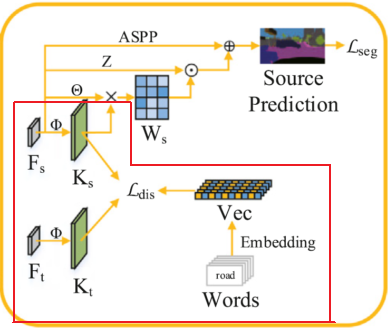
위 구조 중 빨간색 영역으로 표시한 부분이 Knowledge loading 을 수행하는 부분입니다.
각 class를 나타내는 text로 부터 추출된 Semantic vector가 있을텐데,
이를 기반으로 triangular constraint 방식을 사용해서 source 와 target domain의 knowledge를 정렬하는 것입니다.
($L_{dis} $ 를 기준으로 세 부분에서 화살표가 들어오고 있고, 이 때문에 triangular constraint라는 이름을 붙인것인데 아래에서 더 설명드리겠습니다.)
그런데 앞선 Introduction에서 저자가 밀고 나가는 주장이 뭐였을까요?
source domain이건 target domain이건 상관없이 공통되는 common knowledge가 있을테고, 이를 잘 설계하는 것이 저자가 원하는 바였습니다.
예를 들어 자동차(car)는 언제나 4개의 바퀴를 가지고 있고, sidewalk는 보통 road 옆에 분포되어 있는 등의 structural knowledge가 있겠네요.
그러나 보통의 semantic segmentation에서는 scene의 contextual(내용) information에 강하게 의존하기 때문에 앞서 설명드린 structural(구조) knowledge를 loading 하는 것은 매우 어렵다고 합니다.
그래서 저자는 오히려 context-indepent한 knowledge 를 load 하도록 파이프라인을 설계하게 됩니다.
(각 domain의 contextual information에 강하게 의존하는 상황이기 때문에 common knowledge 는 오히려 context-independent 한 knowledge 여야 domain-invariant한, 공통되는 정보이기 때문이죠)
위 그림에서 보이는, class word를 통해 Embedding 된 semantic vector를 사용하게 됩니다.
자 이제 그림과 함께 동작 과정을 살펴봅시다.
class word를 통해 표현된 semantic vector의 경우 미리 pretrained 된 모델을 사용해서 추출하게 되는데 n의 길이를 가지는 vector형태입니다. (본 논문에서 n은 300으로 세팅했다고 합니다.)
각 class마다 1개의 vector가 생성되므로 $ Vec\in\mathbb{R}^{cls \times n} $ 의 shape을 가지게 되겠죠.
그리고 source와 target domain에서 FE(Feature Extractor) 모듈을 통해 추출된 각 feature $ F_s $ , $ F_t $ 가 있을겁니다. 이때 $ F\in\mathbb{R}^{HW \times C} $ 이고, 각각 H: height, W: width, C: channel 을 의미하게 됩니다.
해당 feature 를 통해 knowledge $ K_s $ , $ K_t $ ( $ K\in\mathbb{R}^{cls \times n} $ ) 를 표현할 수 있게 되는데, 학습 가능한 function인 $ \Phi $ 를 통해 모델링 하게 되고 표현 식은 아래와 같습니다.
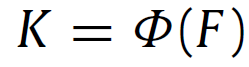
function $ \Phi $ 는 간단하게 2개의 convolution layer로 구성되어 있고, 해당 두 layer를 각각 $ C_0 $ , $ C_1 $ 이라고 해 보겠습니다. 이는 1x1 의 conv이기 때문에 결국 channel 수만 변하게 될 것이고, 각 conv layer의 output shape은 $ F_0 \in\mathbb{R}^{HW \times n} $ , $ F_1 \in\mathbb{R}^{HW \times cls} $ 으로 저자는 세팅하였습니다.
사실 $ \Phi $ 가 2개의 convolution layer라고 설명은 드렸지만, output knowledge K 가 단순 F를 conv연산 2번한 결과로 선정한 것은 아닙니다. 그렇게 되면 $ K\in\mathbb{R}^{cls \times n} $ 라는 결과는 나오지 않게 되죠. 이를 위해 저자는 아래 식을 통해 K를 모델링 합니다.
아래 식의 과정을 통해 HW 라고 하는 축을 날려버림(?)으로써 spatial context dependence를 제거해버렸다 라고 저자는 주장하게 됩니다.
영상에서 spatial 정보를 내포하는 H, W 에 대한 정보를 matmul을 통해 소거함으로써 Common Knowledge K가 spatial 정보에 의존하지 않도록 한 저자의 모델링 의도가 돋보이는 수식입니다.
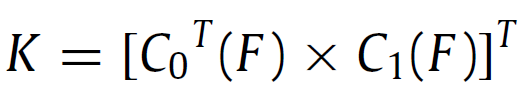
위 식의 shape은 제가 위 설명에서 자세하게 shape을 표기하였기 때문에 매칭해서 보시면 간단하게 이해하실 수 있으실겁니다.
위 식을 통해 구해진 knowledge $ K_s $ 와 $ K_t $ 를 정렬(align)해야 하는데 이때 cosine similarity를 사용하게 됩니다. 아래 식과 같습니다.
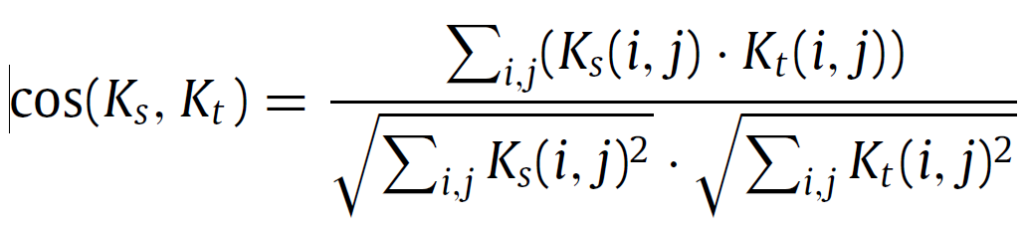
$ K\in\mathbb{R}^{cls \times n} $ 이기 때문에 i는 class 정보를, j는 각 vector의 length n에 대한 정보를 나타내겠죠.
그리고 0과 1사이의 값을 가지는 cosine similarity를 가지고 아래 식을 통해 cosine distance를 구할 수 있게 됩니다.
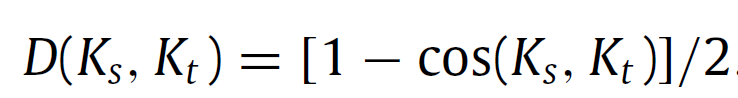
하지만 단순히 위 distance 만을 가지고 source와 target의 knowledge를 정렬하게 되면 rare class에 대해서는 반영이 잘 되지 않는다고 합니다. 예를 들어 pole이나 track과 같은 학습 이미지의 특정 장면에서만 존재하는 class의 경우 road, car 등의 class에 assimilate(동화) 된다고 합니다.
cosine similarity의 경우 두 벡터의 각도 를 표현한 것인데, rare class는 각 벡터에 반영되는 기여도가 매우 적다 보니 cosine distance를 줄이기 위해선 빈도 높은 class에 대한 각도를 맞춰주면 되기 때문에 상대적으로 rare class들은 무시되는 경향이 있는것이죠.
이렇게 rare class의 assimilation(동화) 를 억제하기 위해 class text로 부터 embedding된 semantic vector를 사용하게 되는 것입니다.
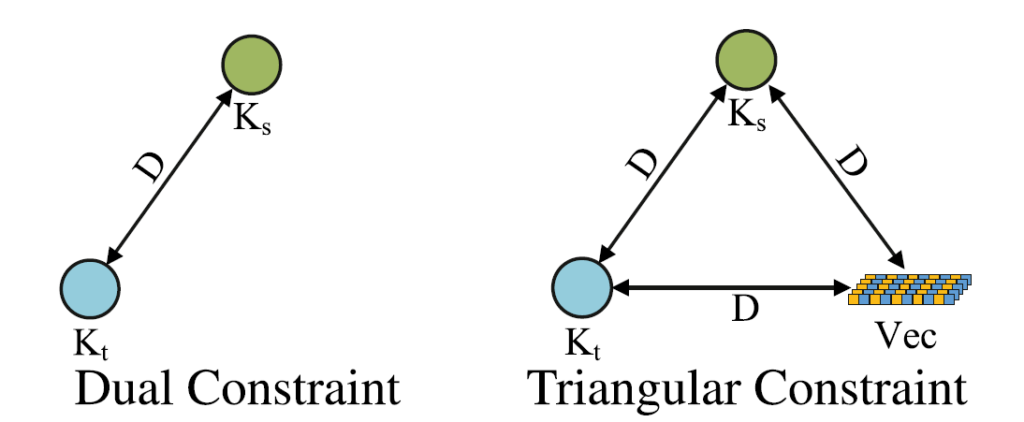
위 그림을 보면 직관적으로 이해하실 수 있는데, 좌측의 Dual Constraint가 아닌, text semantic vector를 사용해서 Triangular Constraint를 모델링 하는 것이죠. 이렇게 되면 rare class에 대해서도 Vec 과의 Distance 계산에 잘 반영이 되기 때문에 앞선 문제가 해결이 된다고 합니다.
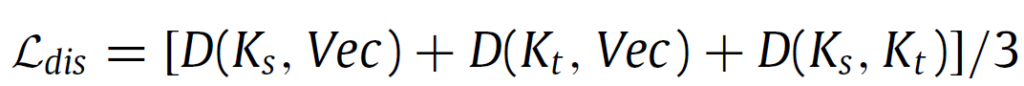
식으로 표현하면 위와 같습니다. 3가지 조합 쌍에 대한 Cosine Distance의 평균으로 표현이 가능하고, 이를 loss로도 설계하였네요.
2.2. Knowledge filtration
그런데 위 $ L_{dis} $ 를 통해 source와 target domain의 knowledge를 정렬한 것은 맞지만, semantic classes 사이의 차이가 그대로 knowledge에 반영되기 때문에 이를 filtering 해 줘야 한다고 저자는 말합니다.
그래서 2.3절의 filtration 과정을 설계한 것입니다.
(사실 위 설명이 직관적으로 잘 이해가 되지 않아 원문도 첨부하도록 하겠습니다.)
(the knowledge from the source and target domains is aligned, the differences among the semantic classes are also stored in knowledge.)
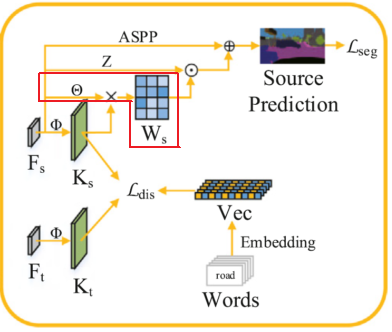
Knowledge filtration 과정은 위 빨간 영역에 해당하는, weight matrix를 계산하게 됩니다.
이는 각 scene마다 등장하는 class 빈도가 서로 다르기 때문에, 특정 scene에서 class 별로 서로 다른 weight를 부여하기 위함이라고 하네요.
저자는 이에 대한 예시로 고속도로의 한 scene에서는 보행자와 자전거가 등장하지 않지만, 이와 반대로 자동차와 교통표지판 class는 매우 빈번하게 등장할 수 있습니다.
다시말해 각 scene별로 등장하는 class 정보가 상이하기 때문에, 각 scene에 따라 class 별 weight 를 조절해서 부여해야 한다는 것입니다. weight matrix W를 통해서 말이죠.
여기서 우리는 weight matrix W의 shape을 예측할 수 있습니다. 우선 위치 정보가 반영되어야 하니 H와 W가 존재할테고, class 정보가 반영되어야 하니 cls 도 있겠네요.
결과론적으로 말씀드리면 weight matrix는 $ W\in\mathbb{R}^{HW \times cls} $ 입니다. 그리고 해당 matrix를 모델링하기 위해 학습 가능한 fuction $ \Theta $ 가 사용되죠. 이는 하나의 1x1 convolution layer로 구성되어 있습니다. channel 수를 C -> cls 로 바꾸기 위함이죠.
그리고 최종적으로 아래 softmax 가 사용된 식으로 weight matrix W가 계산됩니다.
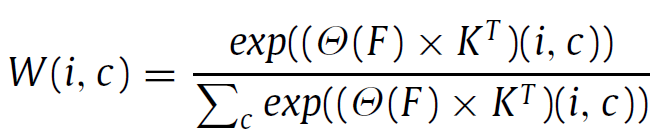
2.3. Knowledge fusion
마지막은 Knowledge fusion 단계입니다.
앞서 구한 weight matrix W를 기존 feature에 fusion 하는 단계이죠.
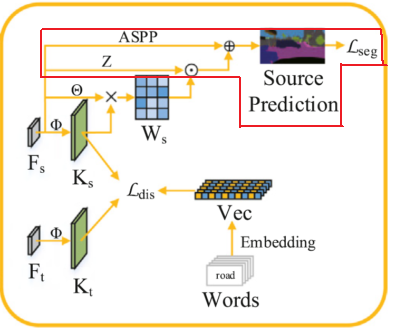
우선 feature F의 channel 수를 바꿔주기 위한 layer Z가 존재합니다. 1개의 1x1 convolution layer로 구성되어 있고, $ Z(F)\in\mathbb{R}^{HW \times cls} $ 의 shape을 가지게 됩니다. weight matrix W와 shape이 같게 되죠. 그리고 둘 사이의 element wise multiplication을 통해 knowledge 정보를 포함한 새로운 feature map을 구할 수 있게 됩니다.
그리고 해당 정보를 ASPP 모듈의 출력과 함께 sum 하게 됩니다.
ASPP 모듈은 Deeplab V2의 모듈을 그대로 사용한 것이라고 하네요.
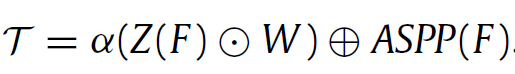
식으로 나타내면 위와 같습니다.
결과적으로, text semantic vector를 통해 common knowledge가 잘 반영된 예측을 수행하고자 했다~ 라고 한 문장으로 정리할 수 있겠네요.
2.4. Training Loss
text semantic vector를 추출하는 모델이 pretrained 된다는 부분 말고 나머지 부분은 전부 end-to-end로 학습이 가능하게 됩니다.
일단 모든 segmentation task에서 사용하는, pixel-wise cross entropy loss를 source domain에 대해 적용하였습니다. 아래 식입니다.
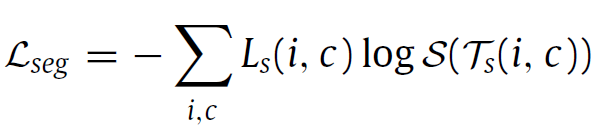
그리고 2.1절 마지막에서 설명드린, Triangular Constraint 를 사용해서 계산한 loss와, 위의 loss를 결합하여 최종 목적함수를 설계하게 됩니다.
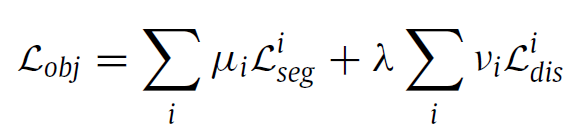
2. method의 전체 그림을 보시면 저자가 설계한 KD 모듈이 3개의 level에 대해서 적용되는 것을 볼 수 있는데 이에 따른 loss 가중치를 다르게 세팅하였습니다.
$ \mu, \nu $ 가 이에 해당하고, 각 scale 별로 [0, 0.1, 1] , [0.25, 0.5, 1] 의 값을, $ \lambda $ 는 0.001 을 사용하였습니다.
3. Experiment

본 논문이 knowledge 기반의 adaptation 방법론을 처음 제시하였기 때문에 기존 DA 방법들과의 비교를 수행하였습니다.
(NonAdaptation 의 경우 baseline으로, 본 논문에서 주장한 KD 모듈을 붙이지 않은, 즉 KD 모듈로 인한 향상폭을 측정하기 위함입니다)
음 그런데 절대적 성능으로만 봤을땐 기존 adversarial 기반 UDA 방법론 중 하나인 ROAD에 비해 2% 이상이나 성능이 낮긴 합니다. 저자는 이에 대해 'not the same technical routes as ours' 라고 하면서도, 기존의 adversarial 기반 방법론에 우리의 knowledge 기반 방식까지 더하면 더 높은 성능을 얻을 수 있다고 말합니다.
(해당 결과를 실험적으로 보이진 않고 말로만 적었네요.... 허허..)
앞선 설명에서 scene별로 rare class를 처리해주기 위해 Knowledge filtration 과정에서 weight matrix를 계산하였습니다. 그렇지만 타 방법론(ROAD) 과 비교했을 때 pole, fence 와 같은 rare class에서 하락 폭이 너무 크네요.
knowledge 기반의 UDA 를 최초로 수행했다는 점에서 contribution을 인정받아 accept이 되었나봅니다. ㅎㅎ
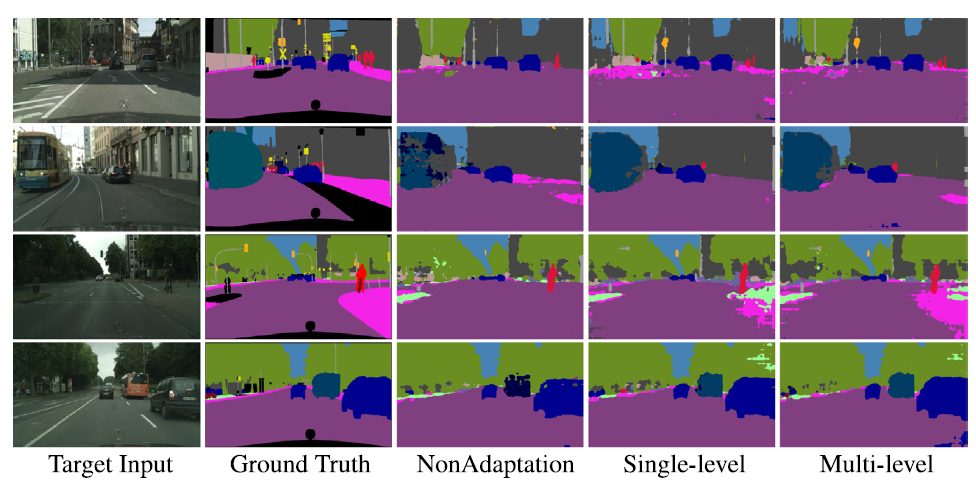
정성적 결과도 타 방법론과 비교는 하지 않고 gt, baseline 그리고 자신들의 KD module을 붙인 결과로만 비교를 하고 있습니다.
위 NonAdaptation과 Multi-level의 결과에서 rare class인 bus에 대한 결과를 비교해보면 저자들의 설계 방식이 어느정도는 들어맞았다고 볼 수 있겠네요.
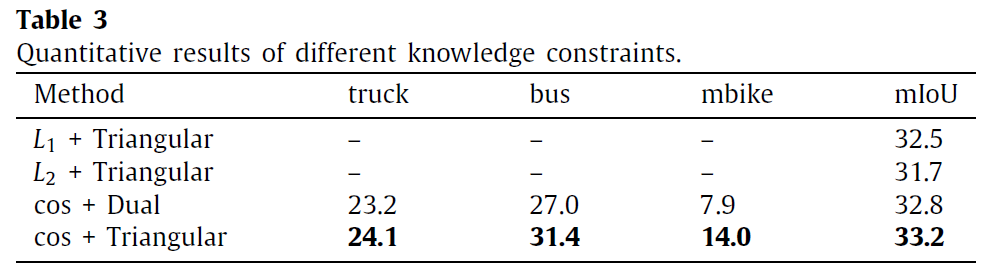
그리고 위 table은 2.1. Knowledge loading에서 constraint를 어떻게 부여하느냐에 따른 결과입니다.
사실 직관적으로 생각해 봤을때 Knowledge 끼리의 loss를 계산할 때 cosine similarity 로 방향 정보만 고려하는 것이 아니라 l1, l2 distance 등으로 벡터의 크기 정보까지 완전 동일하게 맞춰버리면 안되나~ 라고 생각할 수 있습니다. 저자도 그래서 해당 ablation을 준비한 거 같구요.
결과는 cosine 방식이 더 높은 성능을 보이고 있습니다.
저자는 이에 대해 Knowledge에는 noise가 존재할 수 있으며 l1, l2 distance 를 적용할 경우 이런 noise들 까지 완전히 반영해서 완벽하게 동일한 knowledge를 생성하려고 하기 때문에 오히려 Domain Adaptation의 성능을 제한해버릴 수 있다고 합니다.
네 이렇게 리뷰가 마무리 되었습니다.
처음 Introduction을 읽을 때에는 사람의 인식 체계와 비유해서 common knowledge라는 것을 학습해야 한다는 저자의 접근과 주장이 매우 참신하다고 느껴졌습니다. 그리고 method 부분에서 간단한 conv layer 1개 혹은 2개만을 사용해서 저자가 원하는 방향으로 matrix의 shape을 맞춰 나가면서 모델링 해 나가는 과정 또한 직관적이면서 느낀 점이 많았구요.
다만 실험적 결과에서 기존 adversarial 방식에 비해 성능 하락폭이 생각보다 커서 조금 아쉽긴 했습니다. 아마 text로 부터 semantic vector를 미리 추출하게 되는데, 이 semantic vector를 어떻게 추출하느냐에 따라 성능이 많이 좌지우지 해서 그럴 수도 있겠다는 생각이 드네요.
knowledge 기반의 후속 연구가 더 있을진 모르겠지만, 그래도 접근이 참신하니 DA를 위한 새로운 가지로 생각 정도는 하고 있어야겠습니다.
그럼 리뷰 마치도록 하겠습니다. 감사합니다.



