
네 안녕하세요.
해당 논문은 2022년 여름쯤 제가 한창 Depth Estimation 공부를 진행할 때 간략하게 읽었었던 논문입니다.
사실 Depth의 task적인 부분 보다는 Adaptive한 Masking전략에 대부분의 focus를 잡고 읽었기 때문에 Depth task에 대한 여러 지식들이나 흐름에 대해서는 조금 부족할 수도 있습니다. 그래도 최대한 리뷰의 큰 흐름을 잡고 잘 작성해 보겠습니다
1. Premilinary About MonoDepth
우선 시작하기 전 Depth Estimation이 무엇이고 어떤 식으로 동작하는지 잘 모르는 분들을 위한 설명을 진행하겠습니다. 또한, Depth Estimation에 흥미가 있어서 관련 논문을 읽어보고 싶으신 분이 계실 수 있지요. 그래서 해당 분야에서의 근본 논문에 대해 핵심적인 내용 위주로 소개해 드리겠습니다.
monodepth1과 monodepth2라고 불리는 논문인데, Monocular Depth 분야에서는 아주 큰 축을 차지하는 논문입니다.
아 추가적으로 해당 절에서 설명드릴 monodepth1과 monodepth2는 GT depth가 없는 상황에서 Self-supervised 방식으로 학습을 진행하는 방법론들입니다.
1.1 Monocular Depth Estimation
자, 본 논문의 제목에서 Monocular Depth Estimation이라는 용어가 등장합니다.
앞에 붙은 Monocular 라는게 무엇일까요??
Depth Estimation 은 학습 방식에 따라 supervised, unsupervised(self-supervised) 등으로 나뉠 수 있습니다.
반면 Depth 예측 시 필요한 이미지 수에 따라 나누면 Stereo와 Monocular(=Mono) 로 나뉩니다.
Camera Calibration을 통해 Parameter를 계산하고 이를 Matlab tool을 이용해 disparity와 depth map을 구해본 경험이 있으시다면, 해당 과정을 잘 생각해봤을때 예측 시에 2장의 이미지가 입력으로 들어간 뒤 rectification => matching => disparity => depth와 같은 핵심 과정들을 거치지요? 예측 시 사용된 이미지가 2장이므로 해당 방식은 Stereo Depth Estimation이라고 할 수 있습니다.
Stereo Depth Estimation 모델을 학습시키기 위해서는 학습과 예측과정 각각 left, right의 pair image가 필요하게 됩니다. 물론 정확도는 Mono 방식에 비해 높을 수 있지만, 이미지 pair가 항상 필요하다는 치명적 단점이 존재하게 되죠.
그래서 해당 방식보다는 제약조건이 확연히 적은 Monocular Depth Estimation 연구들이 많이 수행되고 있습니다. 그 근간이 되는 방법론이 앞서 언급한 monodepth1과 monodepth2가 되겠구요. Mono Depth 를 수행하는 방법론들은 예측 시 1장의 이미지만을 사용합니다. 그럼 학습때도 1장의 이미지만을 사용할까요?
아닙니다. 그리고 사실 이는 불가능합니다. 2장의 이미지가 있어야 그들 사이에서 disparity를 찾고 이를 통해 depth를 예측할 수 있기 때문이죠.
1.2 MonoDepth 1
monodepth1의 경우는 학습할 때 left-right의 image pair를 사용합니다.
모델은 우선 left->right로 warping을 수행하는 disparity map dr과, right->left로 warping을 수행하는 disparity map dl 을 모델이 각각 예측하게 됩니다.
그 후에는 각 disparity map을 기존 이미지에 적용해서 반대편으로 warping을 진행해야겠죠?
Ir 이미지에 right->left 방향의 warping을 진행해주는 예측 disparity map 인 dl을 적용하면 reconstructed image인 ˜Il 가 생성됩니다. 그 후엔 기존 left image인 Il과 warping을 수행한 image ˜Il 사이에서의 loss가 계산됩니다.
dl을 제대로 예측했다면 Il과 ˜Il의 loss가 낮겠죠? loss 계산에는 L1 loss와 SSIM loss가 함께 사용되고, 학습이 진행되면서 더 정확한 disparity map을 예측하는 방향으로 학습이 진행되게 됩니다.
(학습에 적용되는 더 많은 loss와 detail한 사항들이 있는데 이는 Monodepth1 논문을 참고바랍니다)
위의 과정이 Il 이미지에도 동일하게 수행이 되고, 결과적으로 disparity map을 통해 depth map을 예측하게 됩니다. 아래처럼 말이죠.
1.3 MonoDepth 2
monodepth2 도 monodepth1 처럼 예측 시에 1장의 이미지만을 사용하게 되는데, 둘 사이에는 큰 차별점이 존재합니다.
monodepth2 에서는 학습 시에 left-right의 pair image가 필요 없다는 점이죠. 이건 매우 큰 장점입니다.
그런데 사실 pair image가 필요 없다고 해서 학습 시에 1장의 이미지만을 사용하느냐? 그건 아닙니다.
monodepth2 에서는 left-right pair가 아닌, 시간 frame을 기준으로 한 monocular video를 사용하게 됩니다.
다시 말해 monodepth1는 stereo pair(left & right) 를 사용해서 학습이 진행되었다면,
monodepth2는 monocular video(t-1, t ,t+1)를 사용해서 학습을 진행하는 것이지요.
자, Frame 0을 기준으로 Depth를 예측한다고 생각해봅시다. Frame 0의 이미지는 (a)의 Depth network를 통해 depth Dt를 예측하게 됩니다. monodepth1 에서는 left와 right에 대해 모두 disparity를 구하고 각자 warping을 통해 loss를 계산했는데 음... monodepth2에서는 1장에 대해서만 depth를 예측하죠?
그렇다면 여기선 warping을 하지 않는것일까요? 그건 아닙니다. Depth 예측은 2장의 이미지 사이에서 warping을 통한 loss 계산을 필수적으로 진행해 주어야 하기 때문에 warping 과정도 수행해 주어야 합니다.
왜 2장의 이미지 사이에서 warping이 필수적인지를 묻는다면 아래 그림 3을 참고하시면 좋을 거 같습니다. Depth라는 것은 결국 2장의 이미지 사이에서의 관계를 통해 예측이 가능한 것이니까요.
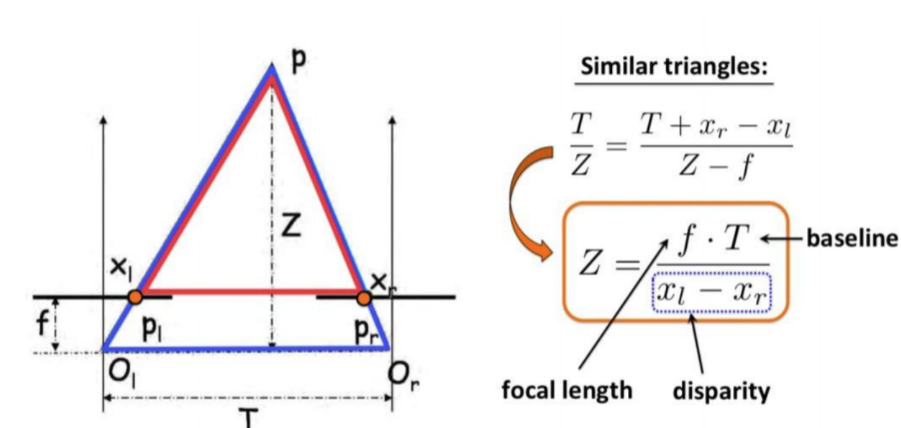
monodepth2 에서는 이를 위해 Pose network (그림 2-(b)) 라는 것을 추가적으로 구성하게 됩니다. Frame t을 기준으로 Depth를 예측한다고 한다면 Frame t과 t-1 사이에서의 Pose 변화, 그리고 Frame t과 t+1 사이에서의 Pose 변화를 예측해야 합니다. 이렇게 Frame 단위에서 camera의 pose변화인 ego-motion을 예측한 뒤 각 Frame끼리의 warping을 통해 monodepth1과 유사하게 loss를 계산하게 되고 학습이 진행되지요.
위 과정에서 warping이라 함은 It를 기준으로 It−1⇒t와 It+1⇒t를 수행하고 각 loss를 계산하는 것입니다.
해당 절에서 설명드린 MonoDepth 1,2 설명은 매우 간략하게 핵심 흐름만 다룬 것이니 자세한 사항은 개인적으로 공부해 보시길 권장드립니다.
2. Introduction
Semantic Segmentation이 pixel단위로 class를 분류하는 task였다면, Depth Estimation은 pixel 단위로 깊이를 예측하는 task입니다. 이 때문에 큰 규모의 labeled dataset을 취득하는데에 비용이 많이 들고, Self-supervised 방식의 연구들이 많이 진행되고 있죠.
해당 논문은 위에서 소개드린 monodepth 1,2와 동일하게 Self-supervised 학습 방식에서의 monocular depth estimation을 수행하게 됩니다.
예전의 연구들은 monodepth와 동일하게 reconstruction 방식을 사용하였습니다. 학습 시 두 장의 이미지가 있다면, 둘 사이의 매칭 관계를 통해 disparity map을 구하고, depth를 예측하는 것이지요.
하지만 이러한 방식은 occluded pixel때문에 blurry한 결과를 발생시킨다는 문제가 존재하게 됩니다.
사실 해당 문제점은 여러 depth 논문들에서 다루고 있는 문제점입니다. 가령 이미지 A,B가 입력으로 들어왔다고 생각해 봅시다. A에서 특정 점이 B에서의 특정 점과 매칭이 되어야 disparity를 구할 수 있을텐데, B에서 그 점이 가려진(occluded) 상태라면 어떻게 될까요? 해당 점에 대해서는 disparity 계산이 불가능하고, 이 때문에 blurry한 깊이 결과가 생성이 되겠죠.
사실 위에서 언급드린 blurry한 결과를 해결하고자 여러 논문들에서 해결책을 제시하긴 했습니다. 제가 기억하는 바론 occluded pixel에 대해 masking을 씌워서 disparity 계산에서 제외시키는 방식이 있었던 거 같네요. 하지만 완벽하게 모든 occluded pixel을 masking하는데에는 한계가 있긴 합니다.
그래서 reconstruction의 이러한 근본적인 문제를 해결해보고자 reconstruction이 아닌 다른 방식으로 depth 문제를 풀어보고자 한 연구들이 등장하기 시작했습니다. pretrained된 stereo depth 모델에서 예측한 값을 pseudo label 삼아서 mono depth 모델로 전달하는 방식이지요.
그리고 여기서 pseudo label의 confidence map을 적용해서 mono depth 모델에게 전달해주는 연구들도 등장하게 됩니다. Stereo depth 모델이 예측한 값을 맹신하지 않고, confidence map을 통해 low confidence 영역은 제외하고서 전이하겠다는 뜻이죠. 이렇게 confidence map을 통해 masking을 하는 방식에도 여러 연구들이 있었는데, 크게 아래와 같이 정리 가능합니다.

(a) 방식은 고정된 threshold를 사용해서 binary masking을 진행하는 방식입니다. 그리고 이때 threshold 값은 pretrained value로 미리 고정되게 되는데, 전체의 학습 이미지에 대해 하나의 동일한 값을 사용하게 되죠.
그렇기 때문에 데이터셋 내 각 이미지에 맞는 개별적 threshold 값 사용이 불가능하고, 이 때문에 성능 향상에는 제한이 존재하게 됩니다.
(b) 방식도 (a)와 마찬가지로 hard한 threshold 방식이긴 합니다만, 미리 값을 뽑아두고 고정하는 것이 아니라 추가적인 regularization term을 이용해서 threshold 값을 학습해 나갑니다. 하지만 이 방식도 그림에서 보시다시피 threshold 값을 기준으로 hard한 방식으로 masking이 진행되기 때문에 성능 향상에는 제한이 존재하게 된다고 저자는 주장합니다.
이러한 제한점을 극복하고자 저자는 (c) 와 같은, soft-thresholding 방식을 제안하게 됩니다. 제가 본 논문을 읽은 목적이기도 하지요. stereo depth 모델이 예측한 값을 pseudo label삼아 mono depth 모델로 전달하는 과정에서, 해당 pseudo depth map을 가지고 confidence map을 예측하게 됩니다. 그리고 confidence map은 저자가 제안하는 soft-thresholding function에 의해 학습된 threshold 값으로 걸러지게 됩니다. 그리고 이렇게 구해진 thresholded confidence map과 pseudo depth labels을 사용해서 최종적으로 mono depth 모델을 학습하게 되는 방식입니다.
Threshold에 대한 설명은 뒤에서 더 할 예정이니 우선 넘어가도록 하겠습니다.
그리고 저자는 추가로 하나의 기법(?)을 더 사용합니다.
위에서 구한 pseudo label을 사용해서 mono 모델이 depth를 예측하게 될텐데, 이 예측값 중에서도 부정확한 영역(=Unreliable part) 이 있을것이고, 이 또한 제거해 줘야 한다는 것이죠.
저자는 uncertainty map을 생성함과 동시에, 2019년에 제안된 pixel-adaptive convolution (PAC layer) 를 함께 사용해서 예측의 부정확한 영역을 한번 더 정제해 주는 과정을 거칩니다.
아래 Method에서 좀 더 자세하게 설명 드리겠습니다.
3. Method

3.1 ThresNet
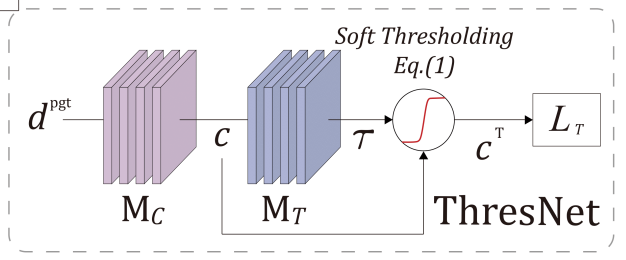
ThresNet은 부정확한 pseudo depth label의 confidence map을 예측하고, soft-thresholding function을 통해 thresholded confidence map을 생성하는 network 입니다.
그림을 보시면 입력으로 dpgt가 들어가게 되는데 이는 이미 self-supervised 방식으로 pretrained된 stereo depth 모델이 예측해 낸 값입니다. 앞서 설명드렸다시피 Mono 논문에서는 이 예측값을 pseudo label 삼아 학습하죠.
그리고 dpgt 는 confidence map을 예측하는 모듈인 Mc 를 거쳐서 confidence map c를 예측하게 됩니다. Mc 모듈로는 간단한 모델인 CCNN 이라는 모델을 사용했다고 하네요. 그렇다면 이렇게 예측된 confidence map c는 pseudo depth label의 잘못된 예측을 방지해주는, 예측 정확도에 귀결되는 '신뢰도' 값을 가지게 되겠죠.
그리고 이 confidence 값을 예측 오류와 연관짓기 위해선 threshold 값을 세팅해야 합니다. 설명이 조금 부드럽지 못할 수 있는데, 간단히 말해서 특정 threshold보다 낮은 confidence는 error가 있는 영역, 높은 confidence는 정확한 영역 이라고 생각하시면 됩니다. 이렇게 threshold 값을 세팅하는 방식으로 위에서 설명드린 그림 4. 의 방식이 있는거구요.
confidence map c 는 threshold 값을 adaptive 하게 예측해주는 모듈 MT 를 거쳐서 threshold T를 예측하게 됩니다. MT는 4개의 conv-GAP로 구성이 되었다고 하네요.
(사실 저 표기가 T가 맞는지 아닌지.. 모호합니다. 그냥 T로 서술하겠습니다)
그리고 최종적으로 ThresNet은 confidence map c와 threshold T를 사용해서 thresholded confidence map인 cT 를 예측해내게 됩니다. 그리고 여기서 cT는 아래의 soft-thresholding function 식을 통해 계산이 됩니다. p는 각 pixel을 의미하고, ϵ 값으로는 10을 사용했다고 합니다.
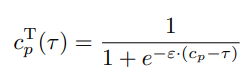
다시 정리하자면 pseudo label의 부정확한 영역을 걸러내고자 confindence map을 사용하였고, 해당 confidence map에서 어떠한 값을 기준으로 error인지 아닌지를 판별하기 위해 유동적으로 학습되는 threshold 값을 도입하였다고 볼 수 있습니다. 그렇다면 threshold값은 이미지마다 다르게 세팅이 된다는 건데, 어떤 규칙(?)으로 세팅이 될까요?
사실 규칙 이라고 표현할 건 아니긴 합니다만, depth 추정이 쉬운 이미지에 대해선 threshold 값이 낮게 세팅이 될테고, 반대로 depth 추정이 어려운 영역에 대해서는 threshold 값이 높게 세팅이 되겠죠. 곱씹어서 생각해보면 아주 당연한 말입니다. 아래 그림과 함께 살펴보시면 될 듯 합니다.

(a)에서 하늘, 도로, 벽 등의 textureless 하고 넓은 featureless 영역에 대해선 threshold 값이 높게 예측된 것을 볼 수 있습니다. pseudo label은 stereo 모델을 통해서 예측이 되고, 이러한 모델들은 left-right stereo matching을 원리로 disparity와 depth를 계산하게 되는데, textureless한 영역들에선 left-right의 매칭을 잘 수행할 수 없기 때문이죠. 쉽게 직관적으로 생각하실 수 있을것이라 생각됩니다.
이와는 반대로 (b)는 한 눈에 봐도 (a)에 비해 특징으로 삼을만한 영역들이 많죠. 이러한 이미지에 대해선 threshold 값이 낮게 예측되게 됩니다.
본 저자는 이렇게 이미지 별로 그 특성을 반영하며 유동적인 adaptive soft-thresholding 방식을 통해 성능 향상을 이루어 냈고, 이는 실험 파트에서도 증명을 하고 있습니다.
3.2 DepthNet and RefineNet
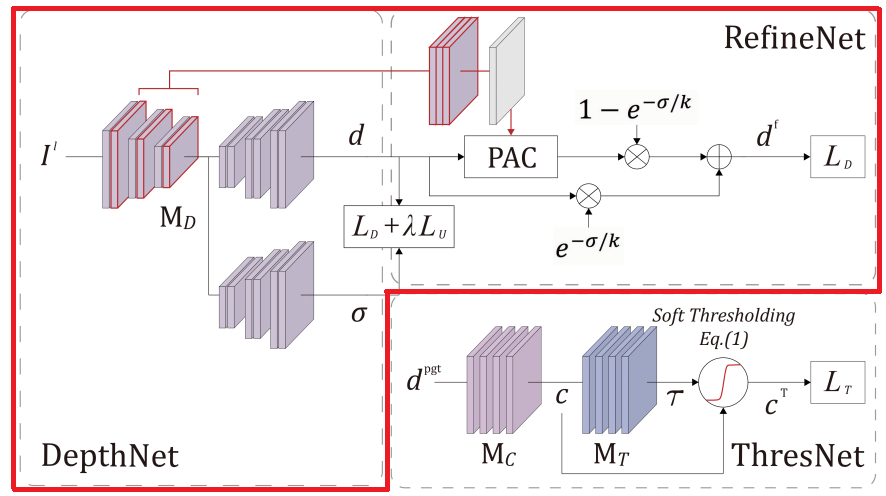
DepthNet과 RefineNet은 위의 3.1절에서 생성된, thresholded confidence map으로 masking된 pseudo label을 사용해서 학습을 진행하게 됩니다.
DepthNet의 경우 U-Net구조를 기반으로 1개의 feature encoder와 2개의 decoder로 구성이 되는데, 각각의 decoder는 depth map d와, uncertainty map σ 를 예측합니다.
서론에서 간략하게 설명드렸다시피 uncertainty map σ는 예측의 부정확성을 조금 완화해 주기 위한 추가적인 방식으로 예측된 depth map 분산을 나타냅니다. 이러한 uncertainty map은 예측된 depth map이 부정확(=unreliable) 할때 더 큰 값을 가지게 됩니다.
그리고 위에서 구한 값들을 통해 아래 식으로 최종적인 depth map df를 예측하게 됩니다.

위 식에서 d'은 PAC layer의 output을 의미하고, k는 1로 세팅하였다고 합니다.
3.3 Training Loss
3.3.1 Threholding loss
ThresNet의 경우 supervised 방식과 self-supervised 방식으로 모두 학습이 가능하고, 비교 결과도 실험 파트에서 제시합니다. 이 둘의 차이는 매우 sparse한 LIDAR depth map의 사용 유무에 따른 차이인데, supervised에서 해당 LIDAR가 어떤 식으로 적용되는지에 대해선 구체적인 언급은 없네요.
LIDAR depth map의 개입이 없는 Self-supervised 학습 방식에서는 어떤 식으로 loss가 계산이 될까요?
여기선 'Self-adapting confidence estimation for stereo' 라는 논문의 방식을 따 왔다고 하는데, ThresNet에서 예측한 thresholded confidence map cT가 있으면 이를 학습하기 위한 pseudo label 을 만든다고 합니다. 이를 논문 표현 그대로 빌려 오자면 'pseudo ground truth of the thresholded confidence map' 이라고 표현하고, 이는 reprojection error를 통해 생성한다고 합니다..
음.. 그런데 말이죠,, 본 논문에서 해당 loss를 설명할때 자세한 설명 과정과 loss는 생략을 합니다. 그리고 위 단락에서 의문이 드는 포인트가 우선 계산방식을 따 온 논문을 보면 for stereo 라는 단어가 들어있습니다. 그리고 'pseudo ground truth of the thresholded confidence map'을 생성할 때 reprojection error 방식으로 생성했다고 언급을 하였는데, reprojection error라는것은 자고로 2장의 이미지가 있을때 적용이 가능한 것이지요..
저자가 이에 대한 구체적 언급과 설명을 피한것으로 보아 이거,,, ThresNet을 학습할 때 stereo 방식으로 학습한게 아닌가.. 라는 의문점이 들긴 하네요. 만약 사실이라면 이 논문은 monocular 가 아닌 stereo depth estimation이 되어야 맞긴 하다만,, 일단은 꼬맹이 학사 4학년의 추측일 뿐입니다..
'Self-adapting confidence estimation for stereo' 논문을 좀 읽어본다거나, 얼마전 저자에게 메일로 따로 코드를 제공받았는데 코드를 까 보면 알 수도 있을 거 같습니다.
어쨋든 confidence map과 pseudo ground truth of the thresholded confidence map 사이의 cross-entropy loss를 계산한다고 합니다.
3.3.2 Depth regression loss
우선 첫번째는 예측 depth map에 대한 loss 입니다.
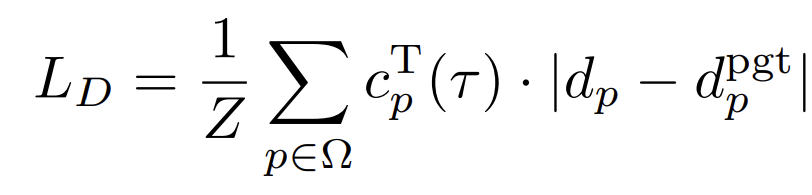
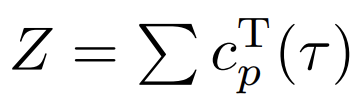
아래첨자에 표기된 p는 모든 pixel에 대해 pixel-wise로 계산 하겠다는 의미이며, d는 그림8의 DepthNet에서 예측한 depth map이고 dpgt는 이미 pre-trained된 stereo model에서 예측한 depth입니다. 한마디로 pseudo depth이죠. 둘 사이의 pixel 단위 loss에다가 ThresNet에서 최종으로 구해진 thresholded confidence map cT 를 곱해줌으로써 부정확한 기존 pseudo label의 문제를 해결하였습니다.
그리고 두번째는 Uncertainty와 관련된 loss 입니다.
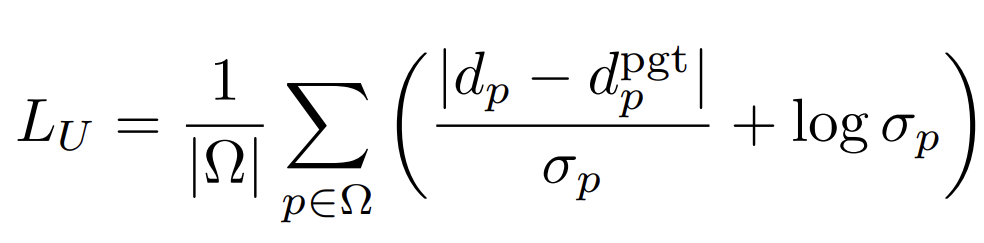
|d−dpgt|를 uncertainty map σ로 나눠줌으로써 최종 mono 모델에서 예측한 depth map의 부정확성을 줄임과 동시에 뒷단에 logσp를 둠으로써 σ가 무한대로 발산하는것을 방지하였습니다. 앞쪽 loss term만 있으면 σ가 무한대로 발산했을때 loss가 0으로 수렴할테니 말이죠.
이 둘을 사용한 최종 loss 는 아래와 같습니다.
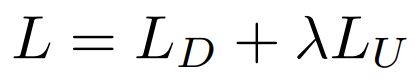
위 식에서 λ 는 10−3을 사용했다고 합니다.
아 부가적으로 3.3.1에서 설명드린 ThresNet을 학습하는 loss와, 3.3.2에서 설명드린 DepthNet, RefineNet을 학습하는 loss는 서로 별개로 학습이 진행된다고 합니다.
4. Experiment

우선 KITTI Eigen Split dataset에 대한 실험 결과입니다.
2번째 column의 Data는 학습 시 사용되는 data의 유형인데, S는 학습 시에 left-right image pairs를 사용 한 것이고, M은 t-1,t,t+1과 같은 monocular video sequences를 사용 한 것입니다.
그리고 Ours에서 D는 ThresNet+DepthNet만을 사용한 것이고, D+R은 ThresNet+DepthNet에다가 RefineNet까지 모두 사용한 결과입니다. 그리고 마지막으로 제일 아래 2개 row에 † 문양은 ThresNet을 self-supervised가 아닌 supervised로 학습했다는 의미입니다. 3.3.1절에서 언급드렸다시피 sparse한 LIDAR depth map를 함께 사용한 것이 supervised 입니다.
사실 본 논문은 모델구조를 제안했다기 보다는 학습 기법에 대한 전체 파이프라인을 제시한것이기에 depth를 예측하는 모델 구조는 단순하게 U-Net과 유사한 구조를 사용하였습니다. 그럼에도 다른 모델적 관점 방법론들보다 성능이 높은것이 인상적이네요. 특히 PackNet-SfM과는 parameter수가 압도적으로 차이가 나는데 말이죠.
그리고 Ours에서 †의 유무, 즉 sparse한 LIDAR depth map를 함께 사용하고 안하고에 따른 성능 변화가 dramatic하지는 않은것도 볼 수 있습니다.
모델 구조 변경보다는, 학습 기법을 통한 성능향상에 관심이 있는 저로써는 전체적으로 꽤나 인상적인 실험 결과입니다.

그리고 KITTI Eigen Split dataset에서 다른 방법론들과 비교한 정성적 결과입니다.
pseudo label의 부정확성을 해결하기 위한 soft-thresholding function, 그리고 mono 모델 예측의 부정확성을 해결하기 위한 Uncertainty map 사용 등의 기법을 통해 예측해낸 본 모델의 결과 (f)를 보시면 타 방법론들에 비해 전체적으로 우수한 결과, 특히 boundary 영역에서 성공적인 예측을 함을 볼 수 있습니다.
(++본 정성적 결과에 GT는 왜 안넣었는지 잘 모르겠네요,,,)

그리고 위는 Cityscapes validation dataset 에서의 정량,정성적 평가입니다.
실험 결과의 경향성은 뭐 KITTI dataset과 유사한데, 본 절에서 좀 의아한 구절을 발견했습니다. 원문은 아래와 같습니다.
The Cityscapes dataset provides only stereo images without the ground truth, and thus the ThresNet trained with the KITTI dataset was used to infer the threshold.
위 문장의 흐름을 해석하면
'Cityscapes는 GT depth가 없다' => '그러므로 ThresNet을 학습하기 위해 KITTI를 사용했다.'
뭐 이런건데 그말은 즉슨 ThresNet을 학습하기 위해선 gt depth가 있어야 한다는 말이 됩니다.
여기에선 사실 저도 좀 헷갈리는 부분이긴 해서 다른 독자분들의 의견을 여쭤보고 싶긴 합니다.
본 논문에서 최종적인 depth 예측을 하기 위한 DepthNet 과 RefineNet을 학습할 때에는 gt depth가 사용이 되지 않습니다. 다만 ThresNet을 미리 학습시킬 때 gt depth가 필요하다는 말이죠.
여기서 제 질문은 pretrained된 모델을 가져와서 쓰는 경우에 그 pretrained 모델을 학습시킬 때 gt 가 사용이 된다면 그건 과연 supervised인가 unsupervised 인가... 입니다.
참 애매모호하긴 합니다만, 제가 현재 진행하고 있는 실험의 있는 경우도 딱 위의 경우와 유사합니다. Unsupervised 상황에서의 실험을 진행하는데, 추가적으로 사용하는 pretrained 모델의 경우에는 학습 시킬때 gt가 사용이 됩니다. IPIU 학회에서도 제 연구를 보고 KAIST에 모 박사과정생분이
'어찌됐건 gt가 사용이 되는건데,, unsupervised 가 맞나요??'
라고 질문을 했었습니다.
흠.. 결론적으론 좀 애매한 거 같긴 하지만, 연구계에서는 이런 경우를 unsupervised라고 칭하기는 하는가봅니다. 본 ICCV 논문도 그렇고, 제가 baseline을 잡고 실험중인 논문도 똑같은 케이스거든요.
실험 섹션에서 잡담이 너무 길었네요. 다음 실험으로 넘어가겠습니다.

리뷰 상단의 그림 4에서 thresholding 방식을 몇가지 소개해 드렸죠? 각 방법론별 성능 결과입니다.
평가지표 중 Abs와 RMSE는 낮을수록 좋고, δ는 높을수록 좋습니다.
다른 fixed및 hard-thresholding 방식에 비해 성능이 개선된 것을 볼 수 있습니다.
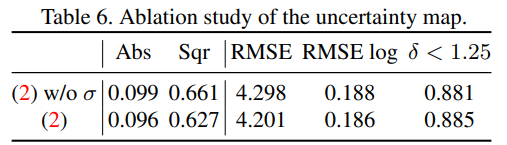
그리고 위 실험결과는 uncertainty map의 적용 유무에 따른 성능 차이를 보여줍니다.
이렇게 기나긴(?) 리뷰가 끝이 났습니다.
이번 리뷰에서는 중간중간에 잡담도 좀 있었고 해서 정신이 없으실 수도 있었을 거 같습니다.
오랜만에 depth관련 논문을 읽어서 remind 할 겸 좋았던 거 같습니다.
본 논문을 읽게 된 목적인 soft-thresholding 방식에 대해선 적용 여부를 코드를 까 보면서 좀 더 고민과 공부를 해봐야 할 거 같습니다.
혹시나 이런 masking 관련된 논문을 읽어보셨거나 아는분이 있으시다면 댓글로 얼마든지 소개해 주시면 감사하겠습니다.
그럼 오늘 리뷰는 이만 마치도록 하겠습니다.
읽어주셔서 감사합니다.



