오늘 소개드릴 논문은 CVPR2017의 Unsupervised Monocular Depth Estimation with Left-Right Consistency 라는 논문입니다. 줄여서 Mono Depth 1 이라고도 불리는 논문입니다.

Abstract
기존의 Supervised 기반의 Depth Estimation 방식은 성능이 좋기는 하지만, model training을 위해선 방대한 양의 ground truth depth data가 필요하다는 문제점이 존재하게 됩니다.따라서 본 논문에서는 위 문제를 해결하고자 depth 정보가 없는 단일이미지 데이터셋에서 depth 정보를 얻어내는 Unsupervised Monocular Depth Estimation을 수행합니다.
보통 depth 정보가 없는 stereo image pair(A, B)에서 depth를 구하고자 한다면 epipolar geometry 를 활용한 disparity map 계산이 필요하게 됩니다. 계산된 하나의 disparity map을 사용해서 B=>A' 로 reconstruction을 시킨 뒤 A와 A' 사이의 reconstruction loss로 network를 train 시키는 방식은 depth image의 quality 가 저하된다고 합니다.
따라서 본 논문의 저자는 disparity map을 하나가 아닌 두개를 생성합니다.
B=>A' 으로 변환시킬 수 있는 disparity map과, A=>B' 으로 변환시킬 수 있는 disparity map을 말합니다.
위에서 말한 left to right disparity와 right to left disparity 의 유사성을 비교하고 같아지는 방식으로 학습을 하게 되는 left-right disparity consistency term 을 추가했습니다.
그리하여 A와 A' 사이의 loss, B와 B' 이미지들끼리 사이의 reconstruction loss 뿐만 아니라 2개의 disparity 끼리의 차이도 모두 고려해 주는 방식을 택합니다. 이와 같은 방식으로 많은 성능 향상을 달성했다고 합니다.

+ Unsupervised Monocular Depth Estimation 에서는 training time에 stereo image pair가 사용되고, test time에 한장의 이미지가 사용이 되는 것입니다.
(논문을 읽기 전 Monocular 라고 하길래 training time에서도 한장의 이미지만 사용이 되는 줄 알았기 때문에 적어 봤습니다,,,)
Contribution
본 논문의 Contribution은 아래 3가지입니다. 핵심은 1번이라고 생각이 됩니다.
- 위 Abstract 에서 말했다시피 left-right disparity consistency 를 적용시킨 training loss를 사용한 end-to-end unsupervised monocular depth estimation
- An evaluation of several training losses and image formation models highlighting the effectiveness of our approach
(여러 training loss와 이미지 생성 모델) - Challenging driving dataset에서의 SOTA 달성.
저자가 모은 outdoor urban dataset을 포함한 3가지 다른 datasets에서의 일반화.
Method
본 논문의 method와 모델 구조에 대해서 설명 드리겠습니다.
본 모델의 핵심 전략은, left image만을 가지고 both disparity를 둘 다 구할 수 있다는 것입니다.

본 모델의 구조는 위 그림의 우측(Ours) 와 같습니다.
앞선 2가지(Naive, No LR) 방식에 대해서 간단하게 설명드리고 본 논문의 방식을 설명드리겠습니다.
left image의 경우 $I^l$, right image의 경우 $I^r$ 이라고 칭하겠습니다.
첫번째로 가장 왼쪽에 있는 Naive한 방식의 경우 CNN model의 input으로 $I^l$가 들어가게 되고 output으로 'right image와 align이 맞는 disparity map'인 $d^r$ 가 생성되게 됩니다. 'right image와 align이 맞다' 는 뜻은 right image로 닮아간다(?)는 뜻이고, 여기서 생성된 $d^r$을 left image에 적용하게 되면 output으로$\tilde{I}^r$ 이 나오게 됩니다. 그러나 저희의 경우엔 predict 과정에서 input으로 들어오는 left image와 align이 맞는 disparity map이 필요하게 됩니다. right image로부터 추가적인 sampling이 필요하게 됩니다.
그리하게 이를 보완한 것이 중간에 있는 No LR 방식입니다.
이 모델은 left image에 align이 맞는 disparity map 인 $d^l$ 을 출력하게 되고, 이를 $I^r$에 적용시켜 sampling 하는 과정을 통해 right image를 $\tilde{I}^l$ 로 reconstruction 시킬 수 있습니다.
본 논문에서는 No LR 방식도 Figure.5 와 같은 depth 불연속 문제가 있다고 말합니다. 아래 그림을 참조해 주시면 될 거 같습니다.

따라서 본 논문에서는 input으로 들어온 $I^l$ 를 가지고 both side view에 대한 2개의 disparity map을 출력하는 모델을 제안합니다. 2개의 disparity map (left=>right, right=>left) 를 출력하고 이를 loss 계산식에 포함시켜서 좀 더 효율적인 학습을 해 나갈 수 있습니다. 2개의 disparity map을 사용하는것이 왜 효율적인지는 아래 Loss 설명 부분의 'Left-Right Disparity Consistency Loss' 를 살펴보시면 이해가 되실겁니다.

모델의 구조와 흐름에 대해 간단히 말씀 드리겠습니다.
전체적인 구조는 Encoder와 Decoder로 구성이 되어 있고, input으로는 single image(left image) 가 들어가게 됩니다.
그리고 output으로는 4개의 different scale (disp4 ~ disp1)에서 각 scale 마다 각각 2개씩의 disparity map을 출력하게 됩니다. (left→right, right→left)
Training Loss
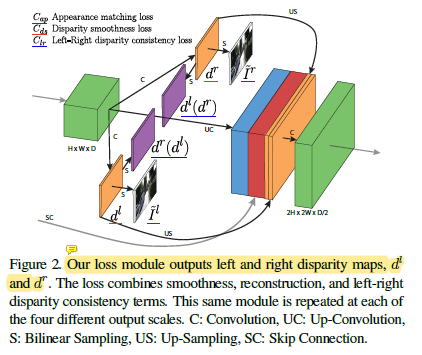
전체 loss C는 4개의 different scale에서의 loss 의 합입니다.

그리고 각 scale별 loss는 아래의 식으로 구하게 됩니다.

위 식을 보면 총 3가지의 loss가 사용되는것을 볼 수 있습니다.
- $C_{ap}$ = Appearance Matching Loss
- $C_{ds}$ = Disparity Smoothness Loss
- $C_{lr}$ = Left-Right Disparity Consistency Loss
하나씩 살펴 보도록 하겠습니다.
1) Appearance Matching Loss

reconstructed image가 기존 이미지와 유사하도록 하는 loss입니다.
예를들어 $I^r$ 이미지에 disparity map 인 $d^l$을 적용하면 reconstructed image인 $\tilde{I}^l$ 가 생성됩니다. 기존의 right image를 가지고 새로운 left image를 생성한 것입니다. 이를 기존의 left image인 $I^l$ 과 비교하는 것입니다.
위에서 말한것은 $C^l_{ap}$ 를 말씀드린 것이고, 동일한 과정을 통해 $C^r_{ap}$ 도 구할 수 있습니다.
여기엔 단순한 L1 loss와 SSIM loss가 사용되는데, 여기서 SSIM loss란 이미지 품질 평가에 쓰이는 것으고 밝기, 구조 등을 비교해서 loss 정보를 계산하는 것이라고 합니다.
2) Disparity Smoothness Loss

두번째는 Disparity의 경계 영역에서 끊어짐 등이 발생하지 않도록 gradient x, gradient y를 측정하는 loss 입니다.
disparity map에서 x, y축 각각에 대해 편미분을 수행하여 축 별로 gradient를 계산하고, 경계영역에서는 gradient의 차이가 급격하기 때문에 exp 로 가중치를 줘서 scale을 줄인것입니다.
disparity 가 locally smooth 하게 하도록 하는 loss라고 합니다.
3) Left-Right Disparity Consistency Loss

마지막은 model을 통해 예측된 left disparity($d^l$)와 right disparity($d^r$)가 유사하도록 하는 loss 입니다. 이 부분은 논문만으로는 이해가 잘 되지 않아 코드와 함께 이해 하였습니다.
1번 loss가 기존 image와 reconstruction image 사이의 loss를 계산한 것이라면, 지금 설명드리는 3번 loss는 기존 예측된 disparity map과 reconstruction disparity map 사이의 loss를 계산하는 것입니다. reconstruction disparity map 라는 말이 잘 이해가 안되실수도 있겠다는 생각이 들어 아래 예시로 설명드리겠습니다.
모델을 통해 나온 left disparity 에 right disparity 를 적용해서 새로운 reconstruction right disparity를 얻고, 이를 기존의 right disparity와 비교합니다. 동일한 과정을 right disparity에도 적용시킨 뒤 2가지 loss를 더한것이 최종 3번 loss가 되는 것입니다.
본 논문에서 주장한 loss는 image끼리의 유사성 뿐만 아니라, 모델에서 출력되는 di sparity map 끼리의 유사성까지 반영을 한다는 점이 성능이 높아진 이유라고 생각됩니다.
Post-Processing
stereo image pair는 중간의 대부분의 영역이 겹쳐져 있지만, 좌 우 끝 영역 조금씩은 겹쳐져 있지 않은 stereo disocclusion 이 존재합니다. 그리고 이 영역은 disparity ramp를 만듭니다. stereo image pair에서 겹쳐지지 않은 영역에서 생성되는 disparity map의 문제점을 해결하고자 하는 후처리 과정이라고 생각하시면 될 거 같습니다.
input image I에 대해 horizontally filp 시킨 image를 I' 이라고 하고 여기서 생성된 disparity map을 d' 라고 하겠습니다. 그리고 이 d'을 flip 시킨것을 d'' 라고 한다면 기존의 d와 d''는 align이 맞을 것입니다. 기존 d에서 좌측의 disocclusion 영역에서 생기는 disparity ramp 를 최소화 하고자, d와 d''를 적절하게 combine 시키는 방식을 사용합니다.
왼쪽 5%는 d''의 왼쪽영역을 사용하고, 오른쪽 5%는 기존 d의 오른쪽 영역을 사용합니다. 그리고 중간 영역에 대해서는 d와 d'의 평균을 사용하게 됩니다.
이러한 post-processing 후처리는 test time에 2배의 시간이 소요되긴 하지만, 정확성이 향상되고, 인공 시각적인 요소가 적어진다고 합니다. 아래에서 보여드릴 성능 표에서 pp라고 표시된 것이 post-processing 과정입니다.
Experiment

표의 제일 아래 row는 본 논문 모델을 평가할 때 stereo camera 로 평가한 경우의 성능입니다. mono의 경우가 stereo 보다 성능이 조금 낮긴 하지만 그렇게 큰 차이가 나지는 않습니다.

위는 정성적인 결과입니다.
GT data에서 위쪽 영역은 하얗게 처리가 되어 있는데 이건 사실 왜그런지 잘 모르겠습니다.. 데이터셋을 한번 봐야 알 거 같습니다.

KITTI dataset 뿐만 아니라, 다른 dataset에서도 일반화된 성능을 보여 줍니다.
처음 쓰는 리뷰여서 그런지 익숙하지 않아서 구구절절 설명하게 되고, 문장도 깔끔하지 않은 거 같습니다. 점차 글 쓰는 실력을 늘려 가도록 하겠습니다.
긴 글 읽어주셔서 감사합니다.



