
오늘 작성 할 논문은 Robust Mutual Learning for Semi-supervised Semantic Segmentation 라는 논문입니다.
2021년에 arXiv에 나온 이후로 다른 학회나 저널에 투고된 기록이 없는것으로 보아
제출을 하지 않은걸까요? 흠이 존재하는 논문일까요?? 흠,, 이에 대해서 잘은 모르겠네요.
뭐 아무튼 리뷰 시작하도록 하겠습니다.
본 논문은 Semi-Supervised 상황에서의 Semantic Segmentation을 수행합니다.
다들 아시겠지만, Semi-Supervised란 Labeled data와 Unlabeled data를 함께 사용해서 모델을 학습시키는 방식이죠.
(보통 한정된 규모의 Labeled data와 대규모의 Unlabeled data를 함께 사용합니다)
여러번 말씀 드렸지만 Segmentation 분야의 dataset은 특히 pixel 단위로 annotation을 수행해야 하기 때문에
labeling 비용이 너무 비싸서 Labeled dataset이 많이 존재하지 않죠.
그래서 Segmentation 분야에서는 Self-Supervised나 Semi-Supervised 분야의 연구가 활발하게 이루어 지고 있습니다.
Semi-Supervised Learning (이하 SSL) 에서는 보통 Pseudo Label을 생성하는 방식을 사용하게 됩니다.
이렇게 Pseudo Label 을 사용해서 학습을 수행하는 연구들은 매우 활발하게 이루어지고 있습니다.
(a) Pseudo Labeling

우선 (a)는 teacher가 student에게 pseudo label을 생성해서 전달 해 주는 방식입니다.
보통 해당 SSL에서는
i) Labeled data에 대해 teacher를 미리 학습시키고,
ii) 학습된 teacher를 통해 Unlabeled data의 pseudo label을 생성하고,
iii) teacher가 생성한 pseudo label을 사용해서 student가 학습하는
뭐 이러한 방식입니다.
직관적으로 잘 와 닿죠??
추가적으로 (a)와 같은 방식에서는 student를 학습 시킬 때 data에 strong-augmentation을 적용하는 경우가 많습니다.
student 학습 시 noise를 더하면 student가 Labeled data로 미리 학습된 teacher에게 더 잘 일반화가 된다는 사실이 앞선 연구에서 증명되고 있는 상황입니다
++ student 학습 시에 부여할 수 있는 noise는 크게 2가지가 존재합니다.
i) Input data에 noise를 부여하는 Data Augmentation 방식.
ii) Student model에 drop-out, stochastic depth 등의 noise를 부여하는 방식.
(위에서 언급한 stochastic depth란 deep CNN에서의 vanishing gradient 등의 문제를 해결하고자
layer의 일부를 무작위로 drop하는 방식을 말합니다)
(b) Meta Pseudo Labeling

하지만 (a)처럼 단순하게 pseudo label을 teacher로 부터 제공받아서 학습하는 방식에는 문제가 있습니다.
pseudo label이 정확하다면 상관이 없지만, pseudo label도 어떻게 보면 특정 모델(teacher)이 예측한 값일 뿐이고
gt와는 다른 잘못된 값이 존재할텐데 이를 보고 학습하게 되면 error가 존재하는 pseudo label에 bias 됩니다.
해당 논문이 작성된 시점 기준의 최근 연구들에서는 해당 문제를 해결하고자 pseudo label의 uncertainty를 계산하기도 하고, (b)에 그려진 방식처럼 student가 teacher에게 feedback을 주기도 합니다.
저자는 이를 meta pseudo labeling이라고 표현했네요.
(c) Mutual Learning
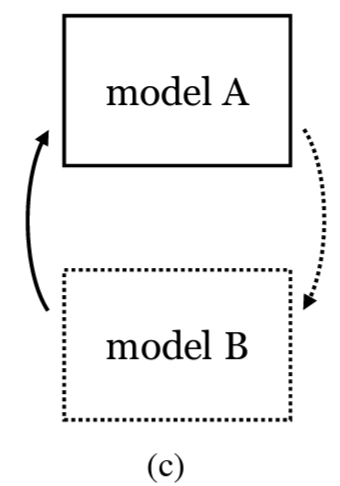
(a) 방식의 문제를 해결하고자 등장한 새로운 학습 기법이 있습니다.
바로 Mutual Learning 방식입니다.
이는 teacher->student 의 단 방향으로 지식(pseudo label)을 전이하는 기존 방식과는 달리,
teacher와 student의 역할을 동시에 수행하는 두 모델이 병렬로 훈련하는 방식입니다.
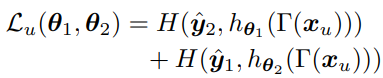
식은 위와 같은데,
어렵게 생각하실 거 없이 1번 모델의 예측을 2번 모델에게, 2번 모델의 예측을 1번에게 전달해서
상호적으로 학습하는 방식이라고 생각하시면 됩니다.
두 모델이 서로 협력하는 방향으로 학습을 진행하며 서로의 단점(ex. noise)은 억제하고 장점만을 배우는 위 학습 방식은 여러 분야에서 적용되며 많은 성능 향상을 이루어 냈습니다.
하지만 Mutual Learning을 진행하는 두 모델은 최종적으로 서로의 동질적인 지식(homogeneous knowledge)으로 수렴되고, 이는 두 모델 각각의 향상 가능성을 억제해 버리는 문제가 생겨버립니다.
좀 더 직관적으로 설명했을 때,
이상적인 상황이라면 각각 다르게 초기화 된 두 모델이 학습해야 할 지식과 정보는 서로 달라서 서로 조금은 다른 방향으로 학습이 진행되어야 하는데 Mutual Learning에서는 서로의 예측값을 그냥 주고 받아버리기 때문에 공통된, 동질적인 지식을 학습하는 방향으로 수렴이 되어버리는 것이지요.
저자는 이를 두 모델의 coupling issue 라고 표현하며 이를 해결하고자 아래의 (d)와 같은 학습 방식을 제안합니다.
(d) Robust Mutual Learning

<Indirect mutual learning with mean teacher>
본 논문에서는 Mutual Learning에서 두 모델의 coupling issue를 해결하고자
첫번째로 우선 위와 같은 구조의 Robust Mutual Learning 이라는 학습 기법을 설계하였습니다.
기존 Mutual Learning 과는 다르게 Mean Teacher 개념을 도입해서 학습에 사용하고 있습니다.
저자는 Mutual Learning에서의 coupling issue가 mutual learners들 사이의 직접적인 상호작용 때문에 발생한다고 추측하였습니다. 즉 model A와 model B가 각각의 예측값을 직접적으로 전달하는 과정에 문제가 있다고 본 것이지요.
이를 해결하고자 Mean Teacher를 통해 각 model의 예측값을 직접적이 아닌, 간접적인 방식으로 주고받는 새로운 학습 방식을 설계하였습니다.
사실 Mean Teacher는 기존
[NIPS 2017] Mean teachers are better role models : Weight-averaged consistency targets improve semi-supervised deep learning results
라는 Semi-Supervised 논문에서 제안된 매우 유명한 방법론입니다.
정리하자면, 본 논문에서는 기존 Mutual Learning이 예측값을 직접 주고받는 과정에서 두 모델이 동일한(homogeneous) 지식을 주고 받는다는 문제를 제시하였고, 이를 해결하고자 기존 SSL의 Mean Teacher를 도입해서 직접적인 예측값의 전달을 피하고 간접적(Indirect) 으로 주고받는 학습 기법을 채택한 것입니다.
이를 통해 각 모델이 이질적인(heterogeneous) 지식을 학습하길 기대합니다.

최종적인 식은 위와 같습니다.
식1 과의 차별점은 두 모델이 서로의 예측 값을 서로 전달하는 것이 아닌,
Mean Teacher에서의 예측값을 두 모델에게 전달하는 과정입니다.
직접적으로 두 모델이 예측값을 주고 받는것이 아니라, 간접적으로 주고받는 것이고 이는 위 그림(d) 에서도 직관적으로 잘 나타나 있으므로 식에 대한 자세한 설명은 생략 하도록 하겠습니다.
<Data augmentation and model noises>
coupling issue를 해결하기 위한 두번째 기법으로는 Data augmentation 기법과,
학습 과정에서 model에 noise를 부여하는 것입니다.
student 모델에 hard augmentation 을 적용함으로써 student가 더 어려운 상황에서 학습이 진행되는 방식의 중요성은 앞선 self-training 연구에서 증명이 되었기 때문에 본 저자는 photometric augmentation을 포함하는 RandAugment와, Cutmix 라는 기존에 제안된 augmentation 기법을 단순 적용하였습니다.
또한 model에게 noise를 부여하는 dropout과 stochastic depth 기법을 적용함으로써 두 모델의 coupling issue를 한층 더 해결하였습니다.

저자는 본인들이 설계한 Indirect mutual learning 방식과 data-model에 noise를 부여하는 방식이
두 모델의 coupling issue를 얼마나 늦췄는지(slow down)를 살펴보는 실험을 진행하였습니다.
3개의 FC layer로 구성된 MLP 모델을 통해 MNIST dataset에 대해 indirect mutual learning을 진행하였습니다.
이때 coupling issue를 살펴보기 위해 두 모델이 예측한 softmax output의 total variation distance를 계산하였습니다.
회색 선으로 표시된 기존의 Direct mutual learning에서는 variation이 낮은 곳에서 빠르게 수렴되는것을 볼 수 있습니다. 이는 두 모델이 다른 비교군에 비해 빠르게 coupling issue가 발생했다고 볼 수 있고, 본 논문에서 강조하는 heterogeneous knowledge를 잘 보장하지 못한 것입니다.
반면 주황색 선으로 표시된 Indirect mutual learning((d) 방식) 의 경우 이를 조금 해결하였고, model에게 noise를 부여하는 본 논문의 방식을 통해 두 모델의 heterogeneous knowledge를 상대적으로 더 잘 보장해 주었다고 볼 수 있겠네요.
<Heterogeneous architecture>
마지막으로 좀 더 직관적이고 확실하게 두 모델에게 noise를 부여하고자,
두 mutual learners 들의 모델 구조를 서로 다르게 설계하였습니다.
이는 dropout과 stochastic depth으로 단순 noise를 주는 것 보다 더욱 확실하게 두 모델에게 heterogeneous한 특징을 부여할 수 있을것이라고 기대할 수 있겠지요.
본 논문에서는 long-range dependency를 보는 Transformer와, local 영역을 보는 CNN으로 두 모델을 각기 다른 heterogeneous한 구조로 설계함으로써 한 단계 더 확실하게 coupling issue를 해결하고자 하였습니다. 이에 대한 효과는 아래 실험 섹션에서 설명 드리겠습니다.
본 논문에서 사용한 CNN 모델은 Deeplabv2 모델이고, Transformer 모델은 SETR 라고 하는 모델을 사용하였습니다.
결론적으로 위에서 설명드린 3가지 기법들을 통해 결국 저자는 Mutual Learning에서는 coupling issue를 해결하는 것이 중요하고, 두 모델이 heterogeneous knowledge를 학습해야 한다고 주장합니다.
Experiment
본 논문에서는 Semantic Segmentation 벤치마크에 흔히 활용되는
Cityscapes와 PASCAL VOC 2012 dataset을 실험에 사용하였습니다.
그리고 SSL 학습 환경에서의 효과를 평가하기 위해 Cityscapes dataset을 랜덤하게 1/30, 1/8, 1/4 의 비율로 랜덤하게 샘플링해서 labeled dataset을 구성하고, 나머지 비율은 GT 정보가 없는 unlabeled dataset을 구축하였습니다.
반면 PASCAL VOC 2012 dataset 의 경우 1/100, 1/50, 1/20, 1/8의 비율로 샘플링하였습니다.

우선 Cityscapes dataset에서의 정량적인 결과입니다.
adversarial 기반의 방법론인 AdvSSL과 S4GAN,
consistency기반 방법론인 ICT, CutMix, CowMix, ClassMix,
mutual learning 과 유사하게 두 모델을 협동하며 학습하는 방식은 ECS, DMT와 비교했을때
본 눈문의 방법론이 모든 sampling 비율에서 높은 성능을 보이는 것을 볼 수 있습니다.
이에 대한 정성적인 결과는 아래와 같습니다. (1/8 에서의 결과입니다)

사람, 자전거와 같은 작은 물체에서 타 방법론에 비해 확실히 좋은 성능을 보여주네요.
자동차와 같은 큰 물체에서도 마찬가지구요.
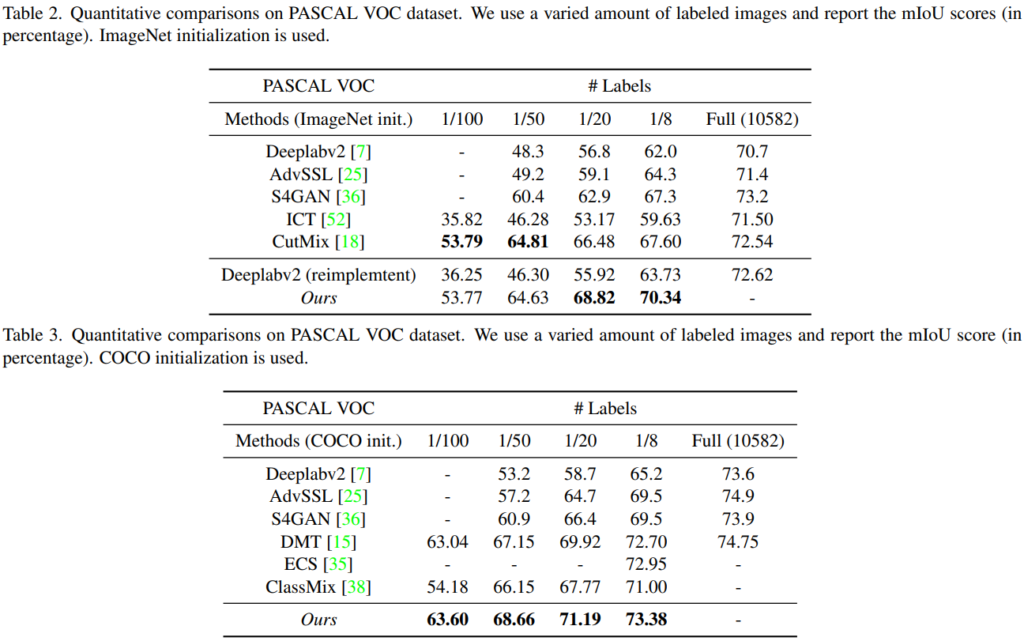
표 2와 3은 모두 PASCAL VOC 에서의 평가 결과입니다.
표 2는 ImageNet으로 사전 학습된 경우이고, 표 3은 COCO dataset을 사전 학습된 경우입니다.
표 2에서는 1/100, 1/50의 비율에서 CutMix에 비해 낮은 성능을 보여주는데에 반해,
표 3에서는 모든 비율에서 타 방법론들을 능가하고 있네요.
해당 부분에 대해서 따로 분석한 내용은 없었고,
또한 표 3에 CutMix의 성능이 리포팅 되어있지 않은 것도 좀 찜찜하네요...

그리고 Mutual learning을 진행할 때 heterogeneous한 모델의 사용해야 한다는 본 논문의 주장을 뒷받침해주는 성능 리포팅 입니다.
위 2가지는 CNN(Deeplabv2) 과 Transformer(SETR) 모델의 각 성능을 의미하고
아래 3가지는 서로 다른 모델 구조의 조합에 따른 성능을 나타낸 것입니다.
CNN/CNN, Transformer/Transformer 의 조합에 비해 CNN/Transformer 의 조합에서 가장 높은 성능을 달성한 것을 볼 수 있습니다.
본 논문의 경우는 Mean Teacher라는 기존에 제시된 방식을 도입함으로써 효과적으로 Mutual Learning을 했다는 점이 꽤나 인상깊었습니다.
뭔가 새롭게 제안한 방식은 없지만,
기존의 것을 조합해서 직관적이지만 확실한 학습 구조를 만들었다는 것에서 뭔가 새로운 접근임을 느꼈네요.
(논문을 쓰려면 꼭 뭔가 새로운 것을 제안 할 필요는 없는가봅니다~~~ 뭐 이런 생각..!)
그런데 또 반대로 생각해보면, 아직 이 논문이 arXiv인 이유가 이 때문일까요,,?? ㅎ
그래도 본 논문에서 주장하는 Mutual Learning에서 heterogeneous knowledge의 중요성은 꽤나 큰 수확이라 생각이 듭니다. 다음에는 더 재밌고 참신한 논문으로 찾아 뵙도록 하겠습니다. 감사합니다.

