
안녕하세요.
오늘 리뷰 할 논문은 CCNet 이라고 하는 segmentation model로써,
Semantic Segmentation을 수행하는 논문인데, Attention 기법을 활용한 모델을 제안합니다.
현재 Semantic Segmentation 관련 실험을 진행중인데, 기존 baseline에서 encoder-decoder model 부분을 바꾸고 싶다는 생각이 들기도 하고, attention 기법에 대해 좀 더 알고싶은 갈망이 있기 때문에 본 논문을 가볍게 읽어보게 되었습니다.
그럼 리뷰 시작하겠습니다.
1. Introduction
Semantic Segmantaion task 의 경우 image의 전체적인 contextual 정보와,
이미지 내 모든 픽셀 사이의 dependency 관계 또한 매우 중요합니다.
저자가 제안하는 CCNet은 criss-cross attention module 이라고 불리는 십자형 attention 연산을 통해
image의 모든 픽셀에서 contextual 정보를 효과적이고 효율적으로 추출(?)합니다.
본 논문이 쓰여질 시점을 기준으로 Semantic Segmentation 의 SOTA는 fully convolutional network (FCN)을 기반으로 하는 모델입니다. (cityscapes dataset 기준 현재 SOTA는 transformer 기반의 방법론입니다)
하지만 이러한 FCN 기반의 방식들은 고정된 kernel로 연산을 수행하기 때문에 local한 receptive field만을 가지게 되고,
그 결과로 이미지 전체의 contextual 정보가 아닌, 좁은 범위(short-range) 에서의 contextual 정보만을 얻게 됩니다.
얻게 되는 정보가 local하다는 문제점을 해결하기 위해 등장한 방식으론 ASPP(Atrous Spatial Pyramid Pooling) 가 있습니다. 해당 방식은 atrous convolution 연산을 통해 kernel의 local한 receptive field를 좀 더 wide 하게 가져가고자 하였습니다.

하지만 본 방식은 kernel 내부의 빈 영역으로 인해 인접 픽셀들 사이의 정보를 손실하게 되고,
결과적으로 dense contextual 정보를 잡아내지 못하게 됩니다.
저자는 이러한 앞선 방법론들의 문제점을 언급하면서,
모든 pixel들 사이의 관계 뿐만 아니라, image에서의 contextual 정보를 효과적으로 얻고자 하였습니다.
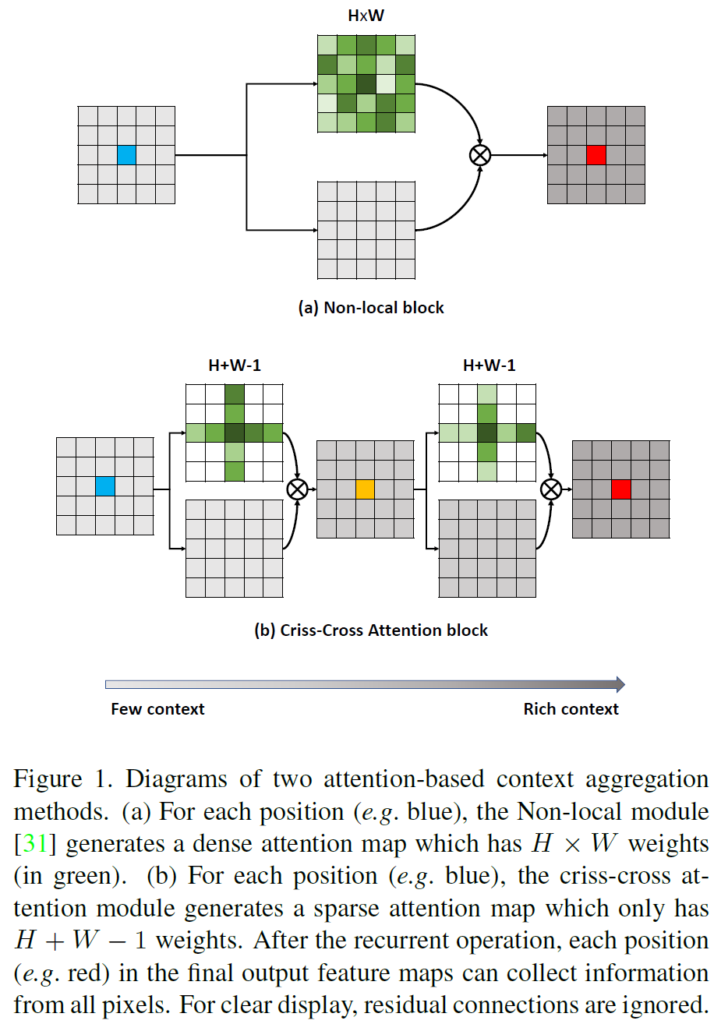
위 그림의 (a)방식은 Non-local block을 사용한,
즉 image 전체에 대해 self-attention 을 진행하는 방식입니다.
그리고 (b) 방식은 본 논문의 핵심인 Criss-Cross Attention block 입니다.
(a) 방식의 경우 input feature map 전체에 대해 dense attention map을 생성하게 됩니다.
전체에 대해 attention을 수행하기 때문에 computing time과 memory가 많이 소모된다는 단점이 있습니다.
그에 반해 본 논문의 방식인 (b)는 feature map의 attention map을 계산할 때에 전체 pixel이 아니라
같은 row 또는 columns을 가지는, 십자가 관계에 있는 pixel에 대해 attention map을 계산하게 됩니다.
100x100 image 기준으로(a)에 비해 1/50 수준으로 적은 계산량을 가진다고 합니다.
해당 과정을 2번 거치게 되면서 각 pixel에 대해 full-image dependencies 를 학습할 수 있게 됩니다.
구체적인 attention 연산은 아래 method에서 더 설명드리겠습니다.
2. Method
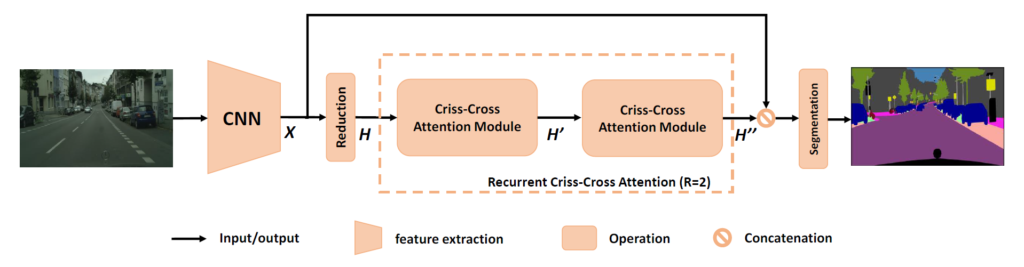
전체 모델의 그림입니다.
Input Image는 CNN 기반의 backbone을 통과시켜서 feature map X를 만들어 내게 됩니다.
본 논문에서는 Resnet 101 을 사용하였는데, 마지막 2개의 downsampling 과정 대신 dilation convolution을 사용해서 detail을 살리고, dense한 feature map을 예측하고자 하였습니다.
이런 과정을 통해 Input Image 기준으로 1/8 작아진 feature map X가 생성되고,
해당 feature map은 reduction을 수행하는 convolution layer 거친 뒤
Criss-Cross Attention Module의 input으로 사용되게 되는 것입니다.
여기서 언급된 reduction이란 dimension reduction, 즉 height-width 의 차원이 줄어드는 것을 말하는데, 본 논문에서 reduction이 어니정도 진행되는지는 말을 안해주네요...
어쨌든 이렇게, feature map X에서 dimension reduction 을 거친 feature map 을 H 라고 부르게 되고,
해당 H 가 Criss-Cross Attention Module 을 통과하게 됩니다.
H 가 Criss-Cross Attention Module을 한번 통과하게 되면 feature map H' 를 얻게 됩니다.
이는 feature map H 에서 horizontal & vertical 방향으로의 contextual 정보만을 담고 있게 됩니다.
왜냐하면 Criss-Cross Attention Module 은 앞서 말했던 거 처럼 같은 row 또는 columns을 가지는 십자가 관계에 있는 pixel에 대해 attention 연산을 수행하는 것이기 때문입니다.
그렇기 때문에 H'은 모든 pixel들 사이의 관계를 나타내지는 못하게 되며,
semantic segmentation을 수행하기엔 정보가 부족합니다.
이 때문에 H' 에 Criss-Cross Attention Module을 적용시켜서 H''을 구하게 됩니다.
이를 통해 H''는 H의 모든 pixel들 사이의 attention 정보를 담아내게 됩니다.
이후 H''은 기존 local representation feature인 X와 concat을 통해 feature fusion을 수행하게 되고
BN, activation 을 수행한 뒤에 최종적으로 segmentation map을 예측하게 됩니다.
전체 구조에서는 위에서 설명한 거 처럼 Criss-Cross Attention Module 이 2번 사용되었는데,
각각의 Criss-Cross Attention Module 의 동작 과정은 아래 그림과 같습니다.
참고로 두 동일한 Criss-Cross Attention Module는 parameter 또한 공유합니다.
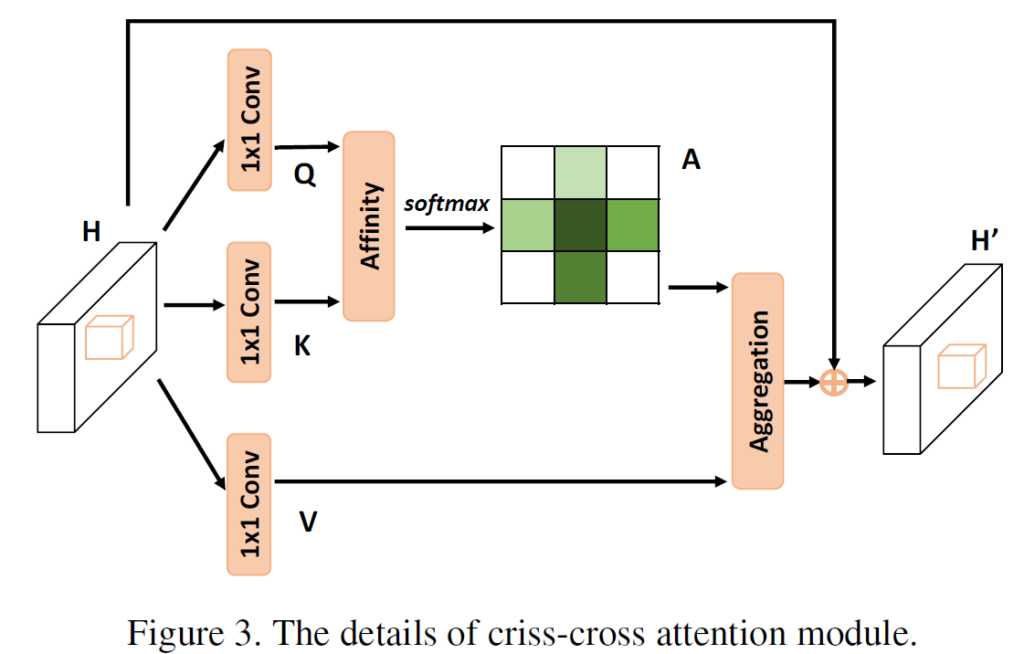
local feature map인 H는
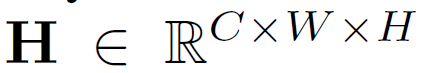
이런 shape을 가집니다.
그리고 1x1 Conv를 통해 아래 shape을 만족하는 Q와 K를 생성하게 됩니다.
channel이 C->C'으로 변경되었습니다.
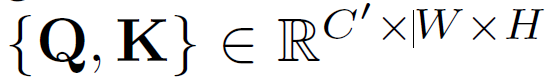
그리고 Feature maps Q와 K의 Affinity 연산을 통해, 아래 조건을 만족시키는 attention maps A를 생성합니다.

H,W는 그대로 인거 같고, channel만 바뀌었는데 어떤식으로 연산이 진행되었는지 감이 안오시죠?
아래에서 Affinity 연산을 설명 드리겠습니다.

해당 구절을 읽어보시는게 이해에 도움이 되실 거 같아 캡쳐본을 첨부 하였습니다.
feature map Q에서 spatial position u가 바뀌면서 생성되는 $Q_u$는 channel축 vector라고 생각하시면 됩니다.
그리고 feature K에서 u의 position (ex. u=(x,y)) 을 가지는 좌표에 대해
same row또는 column을 가지는 십자가 영역의 집합을 $\Omega_u$ 라고 하고,
이 중 i번째 element를 $\Omega_{i,u}$ 라고 표현합니다.
이를 통해 (H+W-1)xWxH 의 shape을 가지는 D를 생성하게 되고,
channel 축에 대해 softmax 연산을 수행하면 최종적으로 Attention Map인 A를 구할 수 있게 됩니다.
Attention map A의 경우 cross 관계인 pixel과의 연관 정보를 channel 축에 담아내게 됩니다.
임의의 pixel을 기준으로 cross 관계인 pixel의 수는 H+W-1 개 이기 때문에,
Attention map A 의 channel이 H+W-1 인 것입니다.
이렇게 cross pixel사이의 관계를 구한 attention map은
앞선 H로 부터 1x1 conv 연산을 통해 만들어진 feature map V 와 합쳐지게 됩니다.
기존 feature map에 대해 attention map을 적용하는, feature adaptation을 수행하기 위함입니다.
(여기서 V는 H와 동일하게 CxWxH 의 shape을 가집니다.)
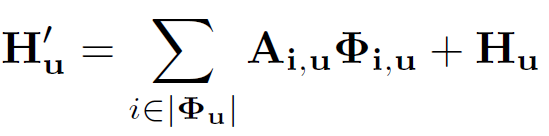
위 식을 통해 Aggregation 을 수행하게 됩니다.
기존의 local feature인 H에 Attention 연산을 통해 구해진 contextual 정보를 더함으로써
pixel-wise representation과 cross-pixels 사이의 관계를 잘 나타내 주는 H' 이 만들어 진 것입니다.
하지만 위의 과정을 한번만 수행하게 된다면 전체 pixel들 끼리의 관계가 아닌,
십자가 pixels 사이의 관계만을 반영하게 됩니다.
십자가에 위치하지 않은, 모든 pixel들의 정보도 반영하기 위해 본 논문에서는 위에서 설명한 Criss-Cross Attention Module을 2번 연속해서 적용하게 됩니다.
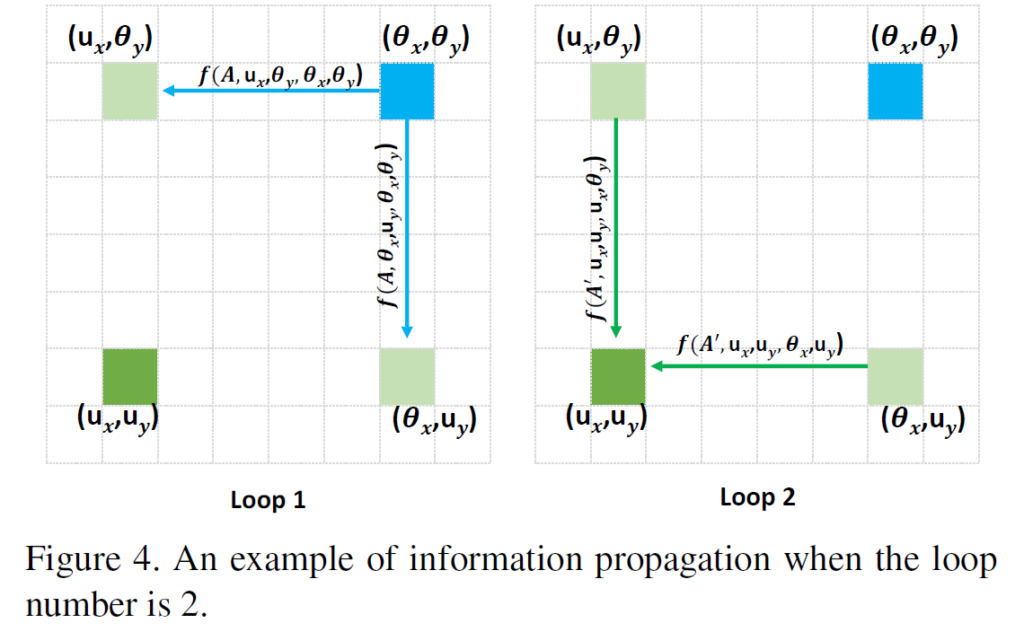
첫번째 module에서 파랑색 point의 정보가 연두색 points로 흘러 들어가게 되고, 두번째 module에서 연두색 points의 정보가 녹색 point에 흘러 들어가기 때문에 결과적으로 파랑색 point의 정보가 녹색 point에 존재하게 됩니다.
이와 마찬가지로, 임의의 다른 point들의 정보들도 다 반영이 되기 때문에 global한 정보를 반영한 feature map이 되게 됩니다.
3. Experiment
본 논문은 feature를 추출하는 backbone으로 앞서 언급했다시피 ImageNet으로 pre-trained 된 ResNet-101을 사용하였습니다. 그리고 Baseline은 Mask-RCNN으로 선정했습니다.
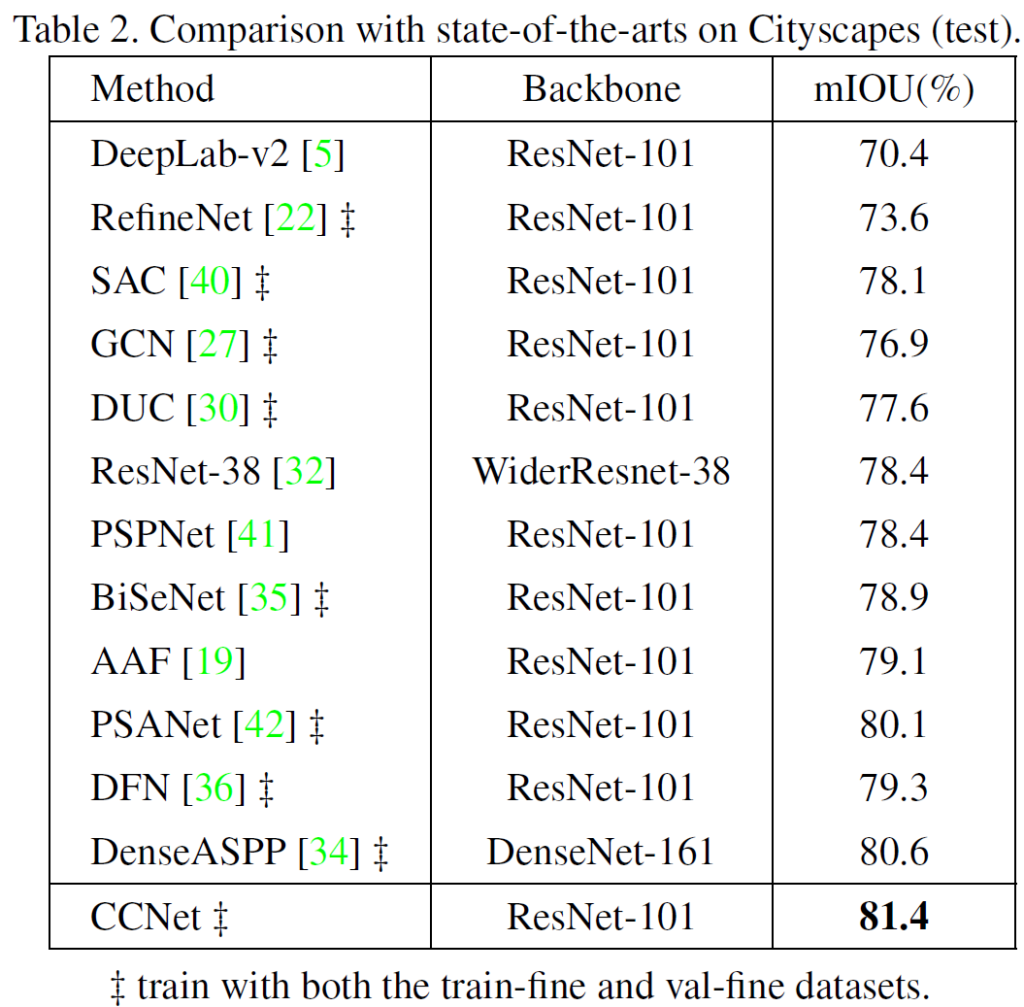
CityScapes test dataset에 대한 평가 결과입니다.
ResNet-38과 DenseASPP 방법론의 경우 ResNet-101이 아닌 다른 strong한 backbone을 사용하였는데도 불구하고,
다른 모든 방법론들을 능가하는 성능을 보여주고 있습니다.
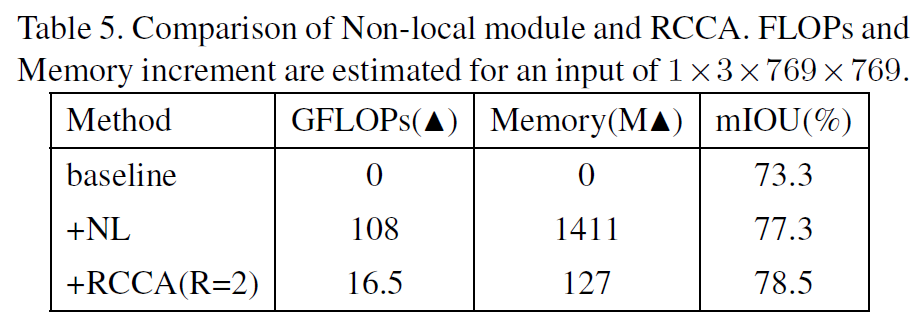
그리고 computing time, memory 에 대한 실험도 진행합니다.
여기서 NL의 경우 리뷰 상단 Figure 1 에서 non-local block을 사용하는 모델인데,
해당 모델에 비해 11배 정도 적은 GPU 사용과, FLOPs 또한 많이 줄인것을 볼 수 있습니다.
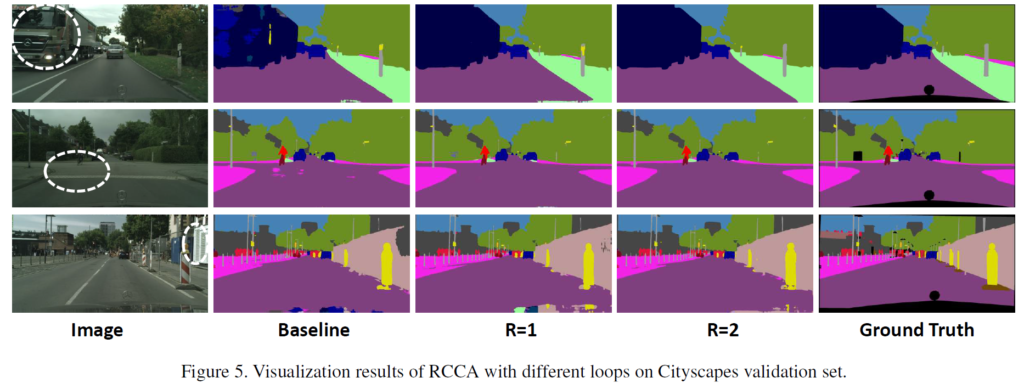
위는 정성적 결과입니다.
저자는 흰색으로 동그라미 친 영역을 misclassification이 자주 일어나는 challenging한 영역이라고 하면서,
이에 따른 예측 결과를 시각화 하였습니다.
R=2에서 물론 좋은 성능을 보이지만, R=1인 경우도 꽤나 훌륭한 예측을 수행하는 것을 볼 수 있습니다.
여기서 R은 저자가 제안한 Criss-Cross Attention Module를 몇 개 사용할 지 나타내는 값입니다.

위는 R=1과 R=2에서 attention map을 visualization 한 것인데,
이미지에서 연두색 +로 표시한 pixel 에 대해 attention map을 시각화 한 결과입니다.
R=1의 경우에는 기준 pixel에 대해 criss-cross path에 대해서만 contextual 정보를 반영하고 있는 것을 볼 수 있습니다.
이와는 다르게, R=2의 경우 전체 영역에 대해 훌륭하게 dense한 contextual 정보를 반영하고 있습니다.
본 논문에서는 criss-cross attention이라는 기법을 통해 criss-cross path의 contextual 정보를 반영하고자 하였고,
이를 두번(R=2) 반복하면서 image 전체 영역에 대한 contextual 정보를 효과적으로 반영하였습니다.
attention 관련된 논문이 익숙하지 않았는데, attention 기법을 직접 적용한 task 논문을 읽음으로써 실제로 attention이란 개념이 어떻게 실제 task 에 적용되는지 알게 되어서 꽤나 유익했습니다.
local receptive field를 가지는 CNN과는 뭔가 느낌과 결이 다르다는 느낌이 드네요,,,
그럼 리뷰 마치도록 하겠습니다. 감사합니다.
'CV 논문리뷰 > Image Segmentation' 카테고리의 다른 글
| [CVPR 2021] Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision (0) | 2023.01.11 |
|---|
