오늘 제가 리뷰한 논문은 HRNet이라고 잘 알려진 backbone 논문입니다.

저번dp 리뷰한 segmentation을 수행하는 MS-UDA 논문에서
pseudo label을 생성하는 모델로 바로 이 HRNet을 사용 했었습니다.
그래서 전 단순히 segmentation을 진행하는 network 겠거니~ 하고 논문을 읽었는데
웬걸 생각보다 대단한 backbone 논문이더라구요. 심지어 TPAMI...!!!!
우리가 흔히 아는 Encoder-Decoder와는 구조 자체가 달라서 새로웠던 논문입니다.
그럼 리뷰 시작하겠습니다.
1. Introduction
우리가 흔히 접할 수 있는 Segmentation, Generation, Translation 등 computer vision 분야에서는
위치(position) 정보가 매우 중요하고, 이를 위해서는 high resolution representation은 필수적입니다.
low resolution은 위치 정보가 소실될 수 있기 때문입니다.
그런데 ResNet과 VGGNet과 같은 기존의 모델들은 통상적으로 input image가 들어오면 이를 저해상도로 encoding을 하는 과정을 수행합니다. 그리고 U-Net과 같이 필요에 따라 decoding을 진행하는 모델도 존재 하겠지요.
대표적으로 classification 모델을 살펴보자면,
LeNet-5의 구조를 따라 AlexNet, VGGNet, GoogleNet, ResNet, DenseNet 등의 많은 모델들이 제안되었습니다.
이러한 분류 모델에서는 convolution 연산을 통해 feature map의 해상도를 점차 low resolution으로 줄여 나갑니다.
아래 그림에서 (a) 에 해당 합니다.

이에 더해, semantic segmentation, pose estimation 등 처럼 이미지에서의 위치 정보가 매우 중요한 task에서는
encoding을 통해 low resolution으로 줄어든 feature map을 다시 high resolution으로 표현해야 합니다.
위 그림에서 (b) 에 해당하겠지요.
하지만 우리가 흔히 아는 DeconvNet, U-Net 처럼 Encoder-Decoder 과정을 통해 해상도를 줄였다가 늘리는 경우에,
기존 이미지가 가지는 정보가 압축되기 때문에 위치, 의미론적 정보 등이 소실될 수 밖에 없습니다.
그렇기 때문에 본 논문에서는 전체 pipeline 동안 high-resolution representation을 계속해서 유지하는 HRNet 이라는 구조를 제안합니다.Encoding을 통해 resolution이 줄어드는 기존 모델과는 다르게, HRNet은 항상 high-resolution을 유지함으로써 의미론적, 공간적 정보를 최대한 보존하는 것이 핵심이라고 생각됩니다.
high resolution에서 low resolution 으로의 conv stream을 paralle하게 연결하고, 각 해상도간에 정보를 반복적으로 교환 하는 모델 구조입니다. 잘 안와닿으실 수도 있는데, 아래에서 모델 그림을 보시면 쉽게 이해하실 수 있다는 생각이 들어서 pass 하겠습니다.
본 논문에서는 제안하는 HRNet 모델을 통해 output이 의미론적인 정보를 풍부하게 담고있고,
공간적인 정보 또한 정확하다고 주장하고 있습니다. 그럼 모델의 구조에 대해 살펴 보겠습니다.
2. Architecture
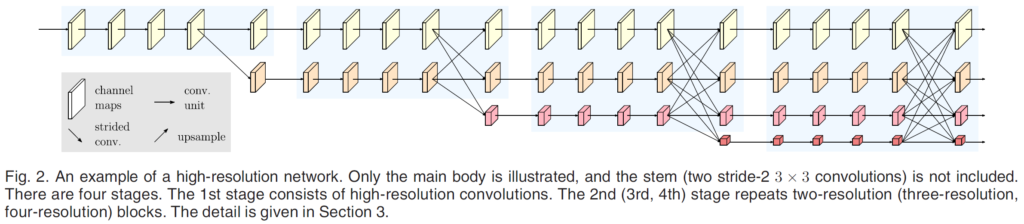
우선 초기 이미지가 input으로 들어가면 stride가 2인 3x3 conv연산을 2번 거쳐서 resolution이 1/4로 downsampling 됩니다. 해당 부분은 위 그림에서는 생략되었고, 1/4로 줄어든 상태에서 상단 모델을 통과하게 됩니다.
보통의 모델에서는 input 으로 들어간 high-resolution의 image가 encoding 과정을 통해서 압축되면서 low resolution으로 바뀌지만, 본 모델에서는 모델의 제일 상단 stream에서 보시는 것과 같이 high resolution이 계속해서 유지되는 것을 볼 수 있습니다.
이와 동시에 high resolution stream 에서 stage가 지날때 마다 한 단계 낮은 resolution의 feature map을 생성하고 이러한 multi-resolution stream 을 parallel 하게 연결한 것을 볼 수 있습니다. 여기서 stage란 위 그림에서 연한 하늘색으로 표시한 각 영역이라고 생각하시면 됩니다.
그리고 stage가 끝날 때 마다 multi resolution의 feature map을 생성하게 되는데, 이때 모든 resolution의 feature map이 함께 관여하는 것을 볼 수 있습니다.
그리하여 high resolution이 가지는 정확한 위치적, 의미론적 정보를 보존함과 동시에,
이를 low resolution의 feature map과 적절히 공유하면서 효과적인 학습이 가능한 모델을 설계한 것입니다.
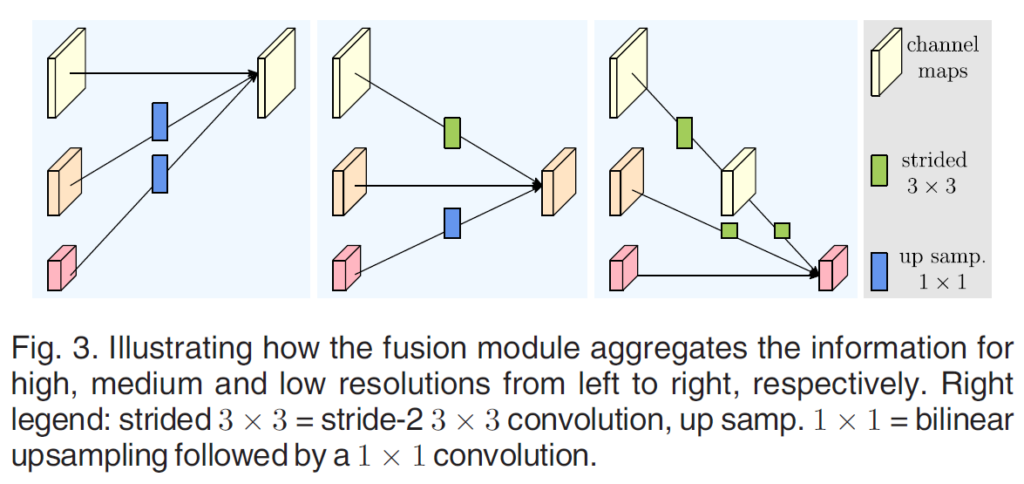
각기 다른 scale의 feature map들이 합쳐진다고 했는데, 그 방식은 별로 복잡하지 않습니다.
output feature map의 resolution에 맞춰서,
resolution을 키워야 할 경우에는 bilinear upsampling을 해 주고,
resolution을 줄여야 할 경우에는 stride2인 3x3 conv 연산을 수행합니다.
그 후 그냥 더해주면 됩니다.
이러한 과정들을 거치면 결론적으로 4가지 종류의 scale이 다른 feature map이 생성되게 됩니다.
이를 처리하는 방식에 따라 3가지로 나뉘게 됩니다.
아래 그림의 (a), (b), (c)가 이에 해당합니다.
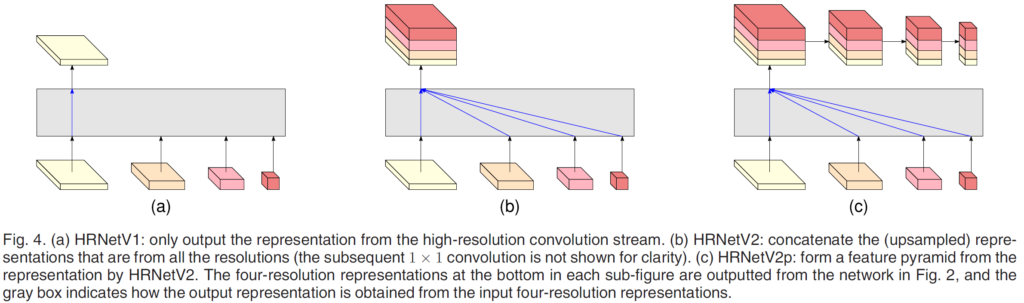
(a) HRNetV1
4가지 중 high-resolution stream 으로부터 생성된 feature map만 사용하는 방식입니다.
본 논문에서는 이 모델을 Pose Estimation 을 수행하는 데에 사용하고, 다른 방법론들과의 비교 실험을 진행합니다.
Pose Estimation 에서는 elbow, wrist 등의 keypoint들의 위치를 잘 찾아야 하는데,
이 때문에 위치정보를 잘 보존하고 있는 high resolution feature map 만을 사용한다고 합니다.
이를 통해 Pose Estimation 에서 필요한 Heatmap을 예측한다고 하네요.
(b) HRNetV2
4가지 feature map을 모두 합쳐서 사용하는 방식입니다.
low resolution의 feature map들은 bilinear upsampling을 통해 high resolution과 동일 해상도를 가지도록 합니다.
이렇게 4가지 feature map을 concat 한 뒤에는 1x1 conv를 태워서 4가지를 잘 mix해 준다고 하네요.
논문에서는 이 모델을 Semantic Segmentation 을 수행하는 데에 사용하고, 다른 방법론들과의 비교 실험을 진행합니다.
위치정보, pixel 에서의 class를 분류하기 위한 의미론적 정보 등
multi resolution에서의 정보가 모두 필요한 Sementic Segmentation의 task에서 해당 모델을 사용합니다.
(c) HRNetV2p
Sementic Segmentation 와 마찬가지로 Object Detection도 multi resolution에서의 정보가 모두 필요합니다.
따라서 HRNetV2 를 사용해도 되지만, 본 논문에서 Object Detection 에서의 비교 실험을 진행할 때에는 HRNetV2p 를 사용했다고 하네요.
3. Experiment
Human Pose Estimation
57000장의 COCO train 2017 dataset으로 HRNetV1 모델을 학습합니다.


5000장으로 구성된 COCO val 에서 예측한 결과입니다.
사실 Pose Estimation task를 잘 몰라서 깊게 분석하지는 않았습니다만,
Input size를 동일시했을때에 타 모델들 보다 성능이 우수한 것을 살펴볼 수 있습니다.
ImageNet Pretrain을 사용했을때 또한 성능의 향상이 존재하네요.
그리고 평가지표중 GFLOPS란 컴퓨터 속도를 나타내는 지표이고,
속도를 뜻한다고 보시면 됩니다.
Sementic Segmentation
Sementic Segmentation은 각 pixel에 class label을 예측하는 task 입니다.
이는 위치관련 정보와 의미론적인 정보가 모두 중요하므로 HRNetV2 모델을 사용해서 실험을 진행하였습니다.
평가 데이터 셋으로는 CityScapes, PASCAL-Context, LIP 를 사용하였는데,
가장 대표적인 CityScapes만 리포팅 하겠습니다.
CityScapes는 총 5000장의 annotation scene images로 이루어 져 있고,
30개의 class 가 존재하지만, 평가할 때에는 19개 class에 대해서 mIOU를 계산했다고 합니다.


평가 지표중 IOU cla.는 19개의 class에 대한 성능이고,
IOU cat. 8개의 category에 대한 성능입니다.
(CityScapes의 annotation은 8개의 category, 그리고 세부적으로 30개의 class로 구성되어 있습니다.) (평가는 19개)
(++ 그런데 여기서 iIOU는 뭔지 잘 모르겠네요..)
Object Detection
118000장의 train, 20000장의 test로 구성된 COCO 2017 dataset으로 학습과 평가를 진행한 결과는 아래와 같습니다.


저자는 본 논문에서 제안한 HRnetV2(p) 가 ResNet과 비슷한 model size와 computation complexity를 가질 경우 성능이 더 우세하다고 주장하고 있고, 실제로도 이를 보여주고 있습니다.
본 논문에서는 vision task를 수행하기 위해 high resolution을 유지하는 network를 제시합니다.
위치적, 의미론적 정보를 보존하기 위함이죠.
그리고 본 모델이 여러 task에 적용될 수 있다고 실험적 결과로도 보여주고 있습니다.
항상 특정 task 관련된 논문만 읽다가, backbone 관련 논문을 읽으니 매우 새로웠습니다.
그리고 본 논문에서 제안한 HRNet의 구조가 기존 모델과는 느낌이 매우 달라서 뭔가 더 신기했던 거 같습니다.
본 논문이 2020년에 나온 논문이니,
그 이후로 나온 backbone 논문이 있다면 기회가 될 때 읽어 봐야할 거 같네요.
(굳이 이후의 것이 아니더라도 말이죠.)