
안녕하세요.
저번 리뷰에 이어 이번 리뷰도 Image Registration 관련 논문입니다.
그럼 리뷰 시작하겠습니다.
1. Image Registration
Image Registration에 대해 잘 모르시는 분이 계실수도 있다는 생각이 들어서 간단하게 설명 해 드리겠습니다.
align이 맞지않는 2장의 Image pair가 있습니다. 한 장을 source, 다른 한 장을 target이라고 할때
source => target으로 align이 맞게 변환을 해주는 그러한 task라고 생각 하시면 될 거 같습니다.
Image Registration에는 많은 방법론들이 존재합니다.
각각에 대해 설명하기에 앞서, 두 평면사이의 변환 행렬인 homography를 구할때의 제약 조건에 대해 소개해 드리겠습니다.
- 동일한 시점에서 회전을 통해 찍은 장면
- 찍는 scene이 평면일 경우
이론적으로는 위의 조건중 하나를 만족할 경우에 두 장의 image를 정렬하는 역할을 homography가 수행합니다.
그럼 이전의 방법론에 대해 설명 드리겠습니다.
1.1 SIFT/SURF + RANSAC
우선 SIFT 와 같은 방법론으로 image pair 에서의 특징점을 찾고 매칭한 뒤 RANSAC 알고리즘을 통한 이상치 제거 후 DLT 알고리즘을 통한 homography 를 예측하는 방법론이 있습니다.
다시말해 image pair에서 찾은 SIFT feature points 쌍 중에서 가장 정확한 4쌍의 매칭쌍을 가지고 homography 변환행렬을 예측하는 것입니다.
위와같은 feature 기반 방법론은 image feature의 퀄리티에 전체 성능이 크게 의존한다는 특징이 있습니다.
matching pairs의 수가 적거나 textureless 영역, illumination 변화가 심한 영역에서는 feature의 분포가 좋지 않다는 단점도 존재합니다.
그리고 위의 SIFT 방식과는 별개로,
non-planar objects, dynamic object가 존재하는 scene에서 추출한 homography의 경우 부정확할 확률이 높으므로 이를 outlier로 처리하는 것이 매우 중요합니다.
homography의 제약조건 2번을 보면 '찍는 scene이 평면일 경우' 라고 되어 있습니다. 이론상의 가정에 따르면 평평하지 않은 non-planar scene 에서의 변환을 나타내는 정확한 single homography matrix는 구할 수 없습니다.
그리하여 본 논문에서는 이를 outlier로 최대한 처리하고자 outlier mask를 제안하는데 이는 뒤에서 다시 설명드릴 예정입니다.
1.2 DNN-based. Supervised
그러다가 DNN 방식의 방법론이 등장하게 됩니다. 그 중에서도 supervised 방식입니다.
supervised 방식에서는 training image pairs 에서 각 쌍끼리의 homography matrix를 GT로 가지게 됩니다.
여기서 H matrix를 GT로 가지고자 training image pairs 를 구성할때에
source image에서 random Homography를 적용해서 target image를 구한 후 training image pairs를 구성하게 됩니다.
다시말해서, supervised 방식에서는 random한 homography 적용을 통해서 합성 image pairs를 구성한 뒤, 이를 training image pairs 로 구성하게 되는것입니다.
하지만 여기서 문제가 발생하게 되는데,
image pairs를 구성하고자 적용한 random homography가 real image에 일반화 하기엔 거리가 먼 점입니다.
아무래도 random H를 적용해서 합성 데이터를 생성하다 보니 현실 세계와는 차이가 있다는 것이겠지요.
1.3 DNN-based. Unsupervised
그래서 Nguyen 라는 사람이 Unsupervised 방식도 제안하게 됩니다.
image pair에서의 homography를 구하고, 둘 사이의 photometric loss를 줄이는 방식인데 이에는 2가지 문제점이 존재합니다.
- feature level에서 loss를 계산하는 방식보다,
image level에서 photometric loss를 계산하는 본 방식이 덜 효과적이다. - 이전 RANSAC같은 경우는 좋은 영역에 대해 선택해서 H를 예측하는데에 반해,
본 방식은 전체 이미지에서 균일하게 H를 예측함
1번 문제점 같은 경우에,
image 단위에서의 단순 photometric loss 적용은 illumination 변화가 극심한 부분같은 경우에 photometric loss가 취약하다는 점을 말하는 것이고
2번 문제점은
non-planar objects, dynamic object같은 영역을 outlier로 고려하지 않고 그냥 균일하게 homography 예측에 반영했다는 점을 말하는 것입니다.
1.4 Ours
저자는 이러한 문제점들을 모두 반영하여서,
image 단위의 photometric loss가 아닌 feature map 단위에서의 loss를 설계하였고,
non-planar objects, dynamic object같은 outlier regions를 제외하기 위한 content-aware mask도 동시에 학습할 수 있는 network를 설계합니다.
아래 그림은 앞서 설명드린 방식의 정성적 결과에 대해 간단하게 나타낸 그림입니다.
H를 통해 warping한 결과 그림만을 겹쳐서 표현한 것인데 확대된 영역을 위주로 봐 주시면 됩니다.

2. Network Architecture

위 그림은 전체 모델 구조에 대한 그림입니다. 크게 3가지로 구성됩니다.
- Feature Extractor -> f(.)
- Mask Predictor -> m(.)
- Homography Estimator -> h(.)
Input으로 들어가는 $I_a$, $I_b$ 는 grayscale의 1채널입니다.
각각의 모듈에 대해 설명 드리겠습니다.
2.1 Feature Extractor -> f(.)
본 방법론에서는 위에서 image에서 pixel intensity value로 photometric loss를 계산하는 다른 방식과는 다르게,
feature map 끼리의 loss를 계산합니다.
그리하여 image에서 feature map을 생성해주는 역할을 f(.)가 하게됩니다.

photometric loss가 아닌, feature map끼리의 loss를 적용했을때의 효과는 아래 그림이 잘 나타내 주고 있습니다.

f(.)를 적용 안했을때의 경우인 row 2 를 보시면,
outlier mask의 대부분이 0으로 매우 sparse 한 것을 볼 수 있습니다.
한마디로 휘도(luminance) 의 변화 때문에 같은 영역인데도 불구하고 다르다고 인지를 하여
대부분의 영역이 삭제 된 것을 볼 수 있습니다.
f(.)를 적용한 row 3(ours) 를 보시면,
feature level에서의 loss 를 계산하게 되므로 휘도의 변화에 강인(불변) 한 결과를 볼 수 있습니다.
2.2 Mask Predictor -> m(.)
이론적으로 non-planar scenes 나, moving object가 포함된 장면에서는 두 image를 정렬할 정확한 homography가 존재하지 않습니다.
이에 더해 RANSAC 에서도 영감을 얻어서, m(.)은
- non-planar scenes 나, moving object가 포함된 영역은 outlier 처리를 해주고
- 1을 제외하고 homography 추정에 많은 기여를 하는 feature map의 영역은 inlier 처리를 해 주는
이렇게 2가지 역할을 하는 Mask Predictor 생성 모듈 입니다.

앞서 구한 feature map인 F 에 mask M을 씌워서
weighted feature maps 인 $G_a$, $G_b$ 를 구하게 됩니다.
2.3 Homography Estimator -> h(.)
$G_a$와 $G_b$ 를 [$G_a$, $G_b$]로 concat해서 h의 input으로 들어가게 됩니다.
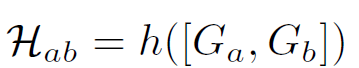
h(.)는 4개의 2D offset vector를 생성한 뒤에, 최종적으로 Homography matrix인 $H_{ab}$ 를 생성하게 됩니다.
3. Loss


$I'_a$ 는 source image 인 $I_a$ 를 $H_{ab}$를 사용해서 target 쪽으로 warping 한 Image를 뜻하고,
$F'_a$ 는 warped image인 $I'_a$ 의 feature map을 의미합니다.
그리고 위의 loss는 $F'_a$ 와 $F_b$ 의 L1 loss 입니다.
real scene에서 단일 homography matrix는 일반적으로
두 view 간의 변환을 정확하게 만족할 수 없음을 고려해서
M’_a와 M_b를 사용해서 정규화 해 준다고 합니다.
(사실 이부분이 잘 와닿지는 않았습니다...ㅎ)
위의 loss만 사용하면 단순히 L1 loss만을 줄이기 위해
$F'_a$ 와 $F_b$ 가 0으로 수렴하는 결과가 초래될 수도 있습니다.
그리하여 아래 loss term을 추가해서,
아래 loss term 이 maximize 하는 방향으로 학습을 시킵니다.
전체 loss에서 -를 붙여주면 되겠죠?

이를 반영한 최종 loss는 아래와 같습니다.
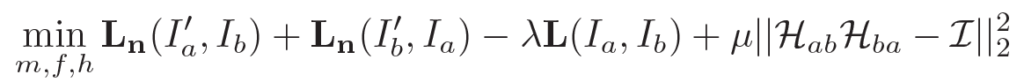
$H_{ab}$ 와 $H_{ba}$ 는 서로 inverse가 되는 방향으로 학습됩니다.
4. Experiment

본 논문에서는 위의 dataset도 제안합니다.
5개의 class 로 이루어져 있고, train data는 80000 pairs,
test data는 4200 pairs 로 이루어져 있습니다.

위는 정성적인 결과와 error를 차트로 나타낸 것입니다.
column 2와 3 에 해당하는 supervised와 unsupervised 는 각각
- Deep image homography estimation.
- Unsupervised deep homography: A fast and robust homography estimation model.
두 논문의 방법론입니다.

row 1,2에서 (a)와 (b)는 dynamic object가 있는 scene에 대한 예이고,
(c)와 (d)는 low-texture, low-light 한 영역이여서 feature에 정보가 적은 경우에 대한 예입니다.
outlier mask를 보시면 (a)와 (b)에서 dynamic object 인 자동차나 분수가 mask에 의해 걸러진 것을 볼 수 있고,
(c) 와 (d) 에서 low-texture, low-light 영역또한 걸러진 것을 볼 수 있습니다.
아래 row 3,4 같은 경우는 ablation study의 정성적 결과를 나타 낸 것입니다.row 3은 $G_a$ 이고, row 4 는 결과 warped source image 인 $]I'_a$ 입니다.
column 2 의 'Attention Only' 는 앞선 loss에서 M’_a와 M_b를 사용해서 정규화 해 주는 부분을 날려버린 것이고,
column 3 의 'RANSAC Only' 는 outlier mask 적용하지 않는 것입니다.
column 2의 경우 저자는
mask learns to highlight the most attractive edges or texture regions without rejecting the other regions
라고 표현을 했습니다.
뒷부분의 rejecting the other regions 가 핵심인 거 같네요.
column 3의 경우는
mask learns to highlight only sparse texture regions (Column 3) as inliers for alignment.
라고 표현 했습니다.
바다 영역같은 경우 학습을 해야하는데 mask로 걸러져 버린 문제점이 발생한 것이 보이네요.
Dataset을 직접 제안했다는 contribution이 있고,
학습할 수 있는 mask를 적용해서 outlier 를 제거해주는 부분이 흥미로웠습니다.
예전에 Depth 관련 논문을 읽으면서도 느낀건데,
이렇게 mask 로 필요한 부분만 filtering 해 주는 작업이 꽤나 중요하고,
설계만 잘 한다면 좋은 성능으로 직결되는 거 같습니다.
그럼 다른 리뷰로 찾아오도록 하겠습니다. 감사합니다.

